
Inhaltsverzeichnis
![]()
SpiegelMining: Think big. Die Artikellandschaft der letzten zwei Jahre zum selberforschen
Heute werden wir Ordnung in das irrwitzige Themen-Chaos bringen, das mit mittlerweile ca. 80.000 Artikeln ganz natürlich entsteht. Und wir generieren eine riesige (!) Themenlandschaft, in der ihr selbst herumforschen könnt.
Dieser Artikel schließt direkt an den vorherigen Artikel an. Im vorherigen Artikel haben wir angefangen zu erforschen, wie SpiegelOnline seine Artikel thematisch einordnet. Wir haben dann festgestellt: Es gibt gleich mehrere verschiedene Artikelmerkmale, die SpiegelOnline zum ordnen verwendet. Rubriken waren das gröbste, Unterrubriken knapp dahinter. Eine nochmals feinere Einordnung waren die Themen. Themen waren keine Unter-Unterrubriken, sondern die wurden separat vergeben.
Es ging abermals feiner: Mit den keywords. Spiegel verteilt eine Liste von Schlagworten pro Artikel, die von den Redakteuren anscheinend frei vergeben werden konnten. Die Keywords schienen auf den ersten Blick sehr ergiebig und erfolgsversprechend. Sie hatten aber auch die typischen Probleme von „Datensätzen aus der freien Natur“ – Redundanzen, Ungenauigkeiten und Fehler.
In diesem Artikel werden wir auf diese Probleme eingehen und sie überwinden. Wir werden Ordnung in eine riesige Masse Keywords bringen und dazu noch eine sehr mächtige Art der visuellen Darstellung finden, die wir in späteren Artikeln dann nutzen werden – Es gibt ja bekanntlich nur eine Breitbandverbindung ins Gehirn: Die Augen.
Eine kurze Wiederholung der Keywords
Eine technische Anmerkung aus dem Alltag des Datensammelns vorweg: Wenn ihr Daten sammelt, indem ihr Webseiten abruft, kann es jederzeit passieren, dass die Ziel-Webseite ihre Struktur ändert und eure Abfragen nicht mehr funktionieren. In diesem Zusammenhang: Herzlichen Glückwunsch an SpiegelOnline zum gelungenen Redesign der Seite! Als ich das eines Morgens gelesen habe, war ich hellwach und habe erstmal gecheckt, ob sie neben dem Design nicht auch was an der internen Seitenstruktur verändert haben. War aber nicht so, die interne Seitenstruktur ist komplett gleichgeblieben, so dass ich nichts anpassen musste. Schwein gehabt! Ob ich das SpiegelMining-Logo dem neuen Design anpasse, muss ich noch entscheiden. Jetzt habe ich natürlich die Chance vergeben das anzupassen und einfach zu behaupten, das wäre vollautomatisch von krassesten MachineLearning-Algorithmen angepasst worden.  Mist. Aber nun zurück ins Studio.
Mist. Aber nun zurück ins Studio.
Wir hatten im letzten Artikel gesehen, dass die meisten Artikel zwischen fünf und zwanzig Keywords besitzen. Die Keywords stehen im Sourcecode. In diesem Artikel waren es zum Beispiel Politik, Ausland, Sergej Iwanow, Kreml, Russland, Wladimir Putin (ein Keyword kann also auch aus mehreren Worten bestehen).
Zum Meßzeitpunkt des letzten Artikels gab es 66278 verschiedene Keywords, von denen nur 10% häufiger vorkamen als zehn mal. Die meisten Keywords sind also sehr klein (in Bezug auf die Anzahl der Artikel, die das Keyword tragen). Mehr als die Hälfte der Keywords kommen überhaupt nur einmal vor. Es gibt aber auch extrem große Keywords, beispielsweise waren die Ressortnamen auch Keywords, aber auch prominente Thematiken (z.B. „flüchtlinge“) kommen auf tausende Vorkommen.
Wir hatten gesehen, dass die Keywords sehr vielversprechender Datensatz zur Artikeleinordnung sind, weil die Einordnungsmöglichkeiten damit extrem vielfältig sind – es gibt astronomisch viele Varianten, für jeden Artikel fünf bis zwanzig Keywords aus rund 66.000 vorhandenen zu wählen. Die thematische Einordnung mittels Keywords kann also sehr genau erfolgen. Es ist nicht wie bei den Themen, wo der Artikel sozusagen auf ein Thema eingeschränkt ist und alle anderen Themen, die auch noch passen würden, leider Pech haben und es nicht mehr in den Artikel schaffen. Zusätzlich dürfen die Keywords anscheinend von den Autoren frei gewählt werden – bei Bedarf wird die Menge der möglichen Keywords über die Zeit also einfach größer.
Wir hatten aber auch gesehen, dass die Keywords eine recht komplexe Sache sind, denn sie sind verrauscht und redundant. Es gibt oft mehrere Keywords zu derselben Sache (z.B. „afd“ 1) und „alternative für deutschland (afd)“)). Oftmals wurde sich erst nach einiger Zeit auf ein Keyword geeinigt, manchmal auch nie, dann laufen die Alternativen nebeneinander her:

Keywords enthalten auch Tippfehler. Auch ein Tippfehler produziert dann ein weiteres Keyword, das mit dem eigentlich gemeinten Keyword zusammen hätte eins sein könnten. Wie gesagt scheinen die Redakteure die Keywords frei eingeben zu können, da ist sowas dann ganz natürlich.
Redundanzen und Rauschen – fragt beliebige Leute, die sich etwas mit Data Science auskennen, welchen Schwierigkeiten sie nahezu bei jedem Projekt begegnen – ich garantiere euch, diese beiden werden häufig vertreten sein. So häufig, dass sie im Grunde nicht als Problem angesehen werden, sondern einfach als Teil der Praxis. Also ist es gut, dass wir jetzt hier ein Verfahren entwickeln, das damit für unsere spezielle Problemstellung klarkommen wird. Das wird euch nicht in jeder Situation weiterhelfen, aber doch ein Gefühl dafür geben, was man machen kann.
Wir hatten im letzten Artikel übrigens auch gesehen, dass Keywords nicht nur verwandt (= viele Artikel gemeinsam) oder unverwandt (= wenige Artikel gemeinsam) sein können, sondern dass es auch aussagekräftigere Beziehung zwischen ihnen gibt. Es gibt beispielsweise auch Keywords, die „echte Untermengen“ anderer Keywords sind. Beispielsweise existiert das Keyword „andreas lubitz“ ausschließlich zusammen mit dem Keyword „germanwings“, aber das Keyword „germanwings“ gibt es auch sonst. Es gibt übrigens auch Keywords, die fast ausschließlich gemeinsam, also in denselben Artikeln, vorkommen.
Eine weitere Erkenntnis war, dass es bei SpiegelOnline zum Jahreswechsel eine Teamorder gegeben zu haben scheint, weniger Keywords einzusetzen. Wir wiederholen diese und untersuchen das noch mal kurz genauer.
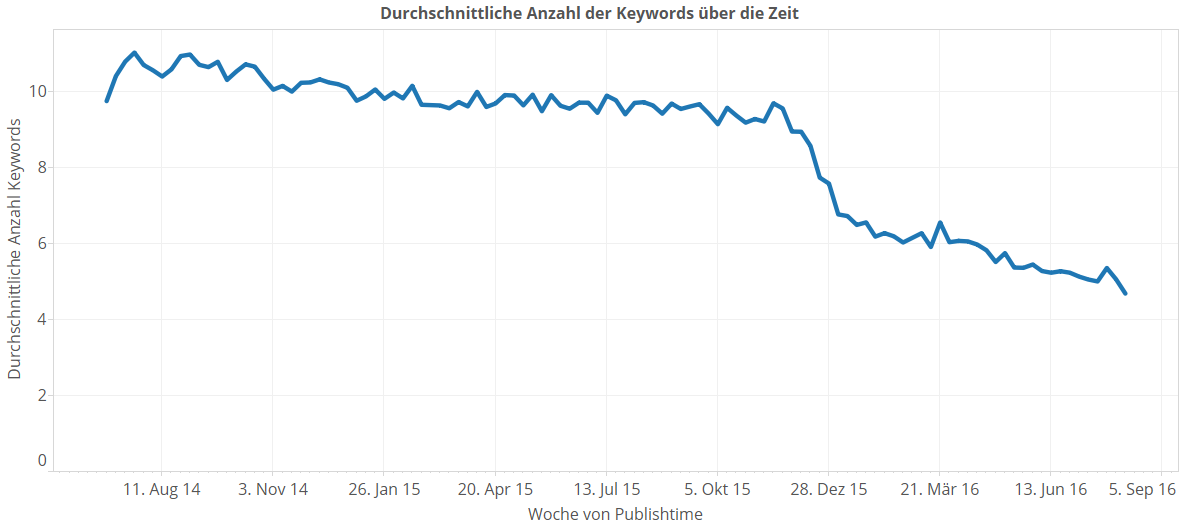
Zum Jahreswechsel von 2015 nach 2016 gibt es einen harten Cut, und seitdem liegt die Durchschnittliche Keywordanzahl eines Artikels nicht mehr bei ungefähr 10, sondern geht eher gegen 5. Ein Gespräch mit dem Team von SpiegelOnline hat hierzu ergeben, dass die Ursache in der Suchmaschinenoptimierung zu suchen ist (Google hat kurz danach seinen Rankingalgorithmus geändert). Falls ein zweiter Grund war, den Wildwuchs zurechtzustutzen, liebes SpiegelOnline-Team: Wir werden heute sehen, dass so ein informationstragender Wildwuchs nicht unbedingt schlecht sein muss, wenn man denn ein Verfahren hat, um dennoch durchzublicken. 
Das Kuddelmuddel durchschauen
Neben den Keywords hatten wir auch noch besprochen, dass diese großen Landkarten, die ich hier gerne mal präsentiere, eigentlich Graphen heißen. Graphen enthalten Elemente, die Knoten genannt werden. Und sie enthalten Verbindungen zwischen diesen Elementen, die Kanten genannt werden. Wir hatten ausserdem gesagt, dass manche Verbindungen wichtiger sein dürfen als andere. Wenn wir dann zum Schluss den fertigen Graphen als Bild darstellen, werden Elemente, deren Verbindung wichtig ist, dann nach Möglichkeit nahe beieinander layoutet. Wir hatten gesehen, dass ein aus den Themen layouteter Graph nicht sehr aussagekräftig war, weil wir diverse Anfängerfehler gemacht hatten. Die Daten selbst schienen nicht sehr aussagekräftig zu sein, wir hatten den Kanten keine Wichtigkeit zugewiesen und auch einfach alle Kanten, die sich uns boten, in den Graphen aufgenommen.
Um das Keyword-Kuddelmuddel mit all seinen Schwächen zu ordnen, definieren wir uns nun eine neue Landkarte, also einen neuen Graphen, indem wir die drei zentralen Fragen dafür beantworten.
- Die Knoten, also die Elemente, die wir miteinander verbinden wollen, sind Keywords. (Übrigens: Wir können also die Knoten wieder als Artikelmengen sehen, nämlich die Menge derer Artikel mit dem jeweiligen Keyword.) Wir nehmen nicht alle Keywords, sondern nur diejenigen, die in mehr als zehn Artikeln vorkommen. Damit sparen wir 90% der Keywords ein (es bleiben 6798 statt 66475), was die Sache deutlich übersichtlicher macht. Wir vernachlässigen also genau das Streugut, was selten vorkommt, und damit auch alle Keywords, die durch Tippfehler entstanden sind, und sparen dadurch Aufwand und Landkartenplatz.
- Welche der 6798 Keywords werden nun verbunden, mit anderen Worten, zwischen welchen Elementen ziehen wir die Kanten? Es kommen diejenigen Keywords in Frage, die mindestens einen Artikel gemeinsam haben. Anmerkung vorweg: Wir nehmen nicht alle möglichen Kanten, denn das wären 324680 Stück. Also filtern wir die Kantenkandidaten aus. Dazu gleich mehr.
- Es bleibt, irgendwie zu bestimmen, welche Kanten Wichtig sind und welche nicht. Mit anderen Worten: Welche Knoten sollen später im Bild tendenziell näher beieinander stehen? Hier gibt es verschiedene Methoden, die wir jetzt kurz auf sehr unmathematische Weise berühren.
Welche Keywordverbindungen sind wichtig?
Ich liefere jetzt mal ein paar Ansätze, wie man die Wichtigkeiten von Kanten errechnen könnte, damit ihr ein Gefühl dafür bekommt.
Erster Versuch: Wir schauen für alle Kanten die Keywords auf beiden Seiten der Kante an. Dann zählen wir, wieviele Artikel diese beiden Keywords gemeinsam haben. Ich nenne diese absolute Zahl der gemeinsamen Artikel Kantendicke. Eine hohe Kantendicke würde dann bedeuten, dass die Verbindung der beiden Keywords wichtig ist. Klingt plausibel, ist aber im Endresultat nicht so gut, weil es zur Folge hat, dass sich die großen Keywords (die mit vielen Artikeln) sich knubbeln. Immerhin haben Keywords mit vielen Artikeln eine größere Chance, große Kantendicken zu erreichen, auch wenn sie gleichzeitig vielleicht ganz viele Artikel besitzen, die nicht im Partnerkeyword enthalten sind.
Anderer, eleganterer Ansatz. Wir nehmen wieder die Artikelmengen der Keywords auf beiden Seiten. Wir gucken: Welche Artikel werden von beiden Keywords zusammen abgedeckt? Und: Wieviel Prozent dieser Artikel haben die beiden Keywords gemeinsam? Je mehr Prozent, desto wichtiger die die Verbindung. Das ist viel eleganter, denn es sind keine absoluten Zahlen mehr drin und es wird auch mit einbezogen, wenn zwei Keywords ganz viele Artikel abdecken, die sie nicht gemeinsam haben. Diese Verbindungsmetrik nennt man Jaccard-Koeffizient. Ist sehr weit verbreitet, für unseren Zweck hier hat er aber auch einen Totschlagsnachteil: Es werden Verbindungen zwischen Keywords bevorzugt, die ungefähr gleich groß sind. „angela merkel“ und „politik“ sind nach unserem Verständnis sicher zwei Keywords, zwischen die eine Kante sollte. Da „politik“ aber unglaublich viel häufiger vorkommt, wäre die Verbindung dennoch unwichtig, denn der Prozentsatz der gemeinsamen Artikel ist gering. Dieses Phänomen der unerwiderten Liebe unter Keywords hatten wir schon mit „andreas lubitz“ und „germanwings“. Über Herrn Lubitz wird nur kurz im Zusammenhang mit Germanwings berichtet, nach unserer Intuition ist die Verbindung also wichtig. Germanwings ist aber auch sonst verbreitetes Nachrichtenthema, was die Verbindung nach dem Jaccard-Koeffizienten unwichtig machen würde.
Wir merzen nun die oben genannten Schwächen aus, indem wir die unerwiderte Liebe mathematisch mit einbeziehen. Betrachten wir wieder zwei Keywords, gerne wieder „angela merkel“ und „politik“ (Andreas Lubitz wird mir langsam zu morbid  ). Messen wir doch einfach, wie wichtig die Keywords gegenseitig füreinander sind. Sagen wir, 80% der Artikel des Keywords „angela merkel“ enthalten auch „politik“. Umgekehrt enthalten aber leider nur 1% der „politik“-Artikel auch „angela merkel“. Dann wäre die Wichtigkeit der dazwischenliegenden Kante einfach die Summe aus beidem: 81%. Man sieht auf den ersten Blick, dass komplett unverwandte Keywords irgendwo bei 0% liegen, Verbindungen mit unerwiderter Liebe um die 100%, und beidseitig verliebte Keywords bei ungefähr 200%, wobei alle Zwischenstufen möglich sind. Fertig ist das Verfahren, mit dem ich bestimme, welche Verbindungen füreinander wichtig sind. Klingt jetzt einfach, aber da waren viele Stunden und Tage an Experimenten mit verschiedensten Wichtigkeitsmaßen nötig, bis sich das rauskristallisiert hat.
). Messen wir doch einfach, wie wichtig die Keywords gegenseitig füreinander sind. Sagen wir, 80% der Artikel des Keywords „angela merkel“ enthalten auch „politik“. Umgekehrt enthalten aber leider nur 1% der „politik“-Artikel auch „angela merkel“. Dann wäre die Wichtigkeit der dazwischenliegenden Kante einfach die Summe aus beidem: 81%. Man sieht auf den ersten Blick, dass komplett unverwandte Keywords irgendwo bei 0% liegen, Verbindungen mit unerwiderter Liebe um die 100%, und beidseitig verliebte Keywords bei ungefähr 200%, wobei alle Zwischenstufen möglich sind. Fertig ist das Verfahren, mit dem ich bestimme, welche Verbindungen füreinander wichtig sind. Klingt jetzt einfach, aber da waren viele Stunden und Tage an Experimenten mit verschiedensten Wichtigkeitsmaßen nötig, bis sich das rauskristallisiert hat.
Für die Visualisierung: Kanten sinnvoll weglassen.
Wir können jetzt für jedes Thema sinnvoll errechnen, wie verwandt es zu anderen Themen ist. Würden wir den Graphen nur im Speicher haben wollen zum daraus Messwerte zu ziehen oder sonstige Mathematik zu betreiben (wie damals auf dem Graphen der Spiegelredakteure), wären wir jetzt fertig.
Uns geht es jetzt jedoch darum, diese riesige Landkarte auch zu visualisieren. Wir werden später noch erörtern, wie eine solchen Landkarte zum visuellen Vermitteln von sehr vielen, verschiedenen Informationen nutzen kann.
In der Abbildung kann man aber nicht alle 324680 Kanten brauchen. Erstens hat man dann vor lauter Linien einfach eine große, farbige Fläche, und Anzeigeprogramme werden enorm langsam, weil jede Kante einzeln gerendert wird. Das ist impraktikabel, ließe sich aber durch simples nicht-darstellen von weniger wichtigen Kanten lösen. Zweitens und viel wichtiger: Bei den meisten Algorithmen, die Graphen in schöne Bilder layouten, steigt der Aufwand mit vielen Kanten ins unermeßliche. Ehe man einen halben Tag nur mit der Berechnung der Landkartendarstellung verbringt, filtert man lieber die 90% der Kanten raus, die wenig zur Gesamtstruktur beitragen, und braucht fortan nur noch ein paar Minuten oder Sekunden für das Errechnen einer schönen Darstellung.
Es mag jetzt verlockend erscheinen, einfach alle Kanten herzunehmen und zum Beispiel zu sagen: Wir nehmen nur die 20% Kanten mit dem höchsten Wichtigkeitswert. Sozusagen einen globalen harten cut. Das ist aber ungut, weil das Resultat die Gesamtstruktur des originalen Graphen wahrscheinlich nicht realistisch wiedergeben wird. Es kann auch Knoten geben, die nur Kanten haben, die nicht soooo wichtig sind. Diese Knoten würden durch einen globalen harten Cut vereinsamen.
Besser ist es, lokal vorzugehen. Wir laufen über alle Knoten und sagen: Jeder Knoten darf seine persönlichen 20% wichtigsten Kanten wählen, die dann drin bleiben. So erhält man sehr schön die lokalen Strukturen und schmeisst trotzdem die unwichtigen Kanten raus. Statt der 324680 möglichen Kanten bleiben im konkreten Beispiel dann 23749 über.
Endlich, endlich was zum gucken: Wir stellen den Graphen dar
So, genug des länglichen Textes – jetzt gibt es endlich mal was zu sehen. Wir nehmen jetzt unseren Graphen mit gefilterten Knoten bzw. Keywords sowie sauber gewichteten und lokal gefilterten Kanten. Den layouten wir erstmal völlig zufällig. Danach sehen wir die wichtigen Kanten als kurze starke Federn an (ja, Federn im ganz physikalischen Sinne). Die unwichtigeren Kanten sind dagegen lange, schwache Federn. Und darauf machen wir eine Physiksimulation, in der sich die Federn dann von alleine schön zurecht zurren, so dass im Graph die Knoten mit wichtigen Verbindungen tendenziell nahe beieinander liegen. Schauts euch im folgenden Video an, man sieht, wie sich Strukturen herausbilden (hier könnte es sich lohnen, auf Fullscreen umzuschalten):
Die Knotenfarben repräsentieren übrigens dasjenige Ressort, die den jeweiligen Knoten dominiert (also mehr als 50% Artikel einnimmt). Dominiert kein Ressort, so ist ein Knoten grau. (Achtung: Die Farben im Video sind andere als die im tatsächlichen Graphen später.)
Wie, ihr seht fast keine Knoten? Das liegt daran, dass der Graph so unglaublich riesig ist. Man sieht ein paar wenige, sehr sehr große Knoten (die Größe repräsentiert die Artikelzahl mit dem jeweiligen Keyword), aber man sieht nicht einmal einen Bruchteil der ca. 6700, aus denen der Graph besteht. Wir veranschaulichen mal die schiere Größe des Graphen, indem wir schrittweise reinzoomen. Hier ist der ganze Graph:
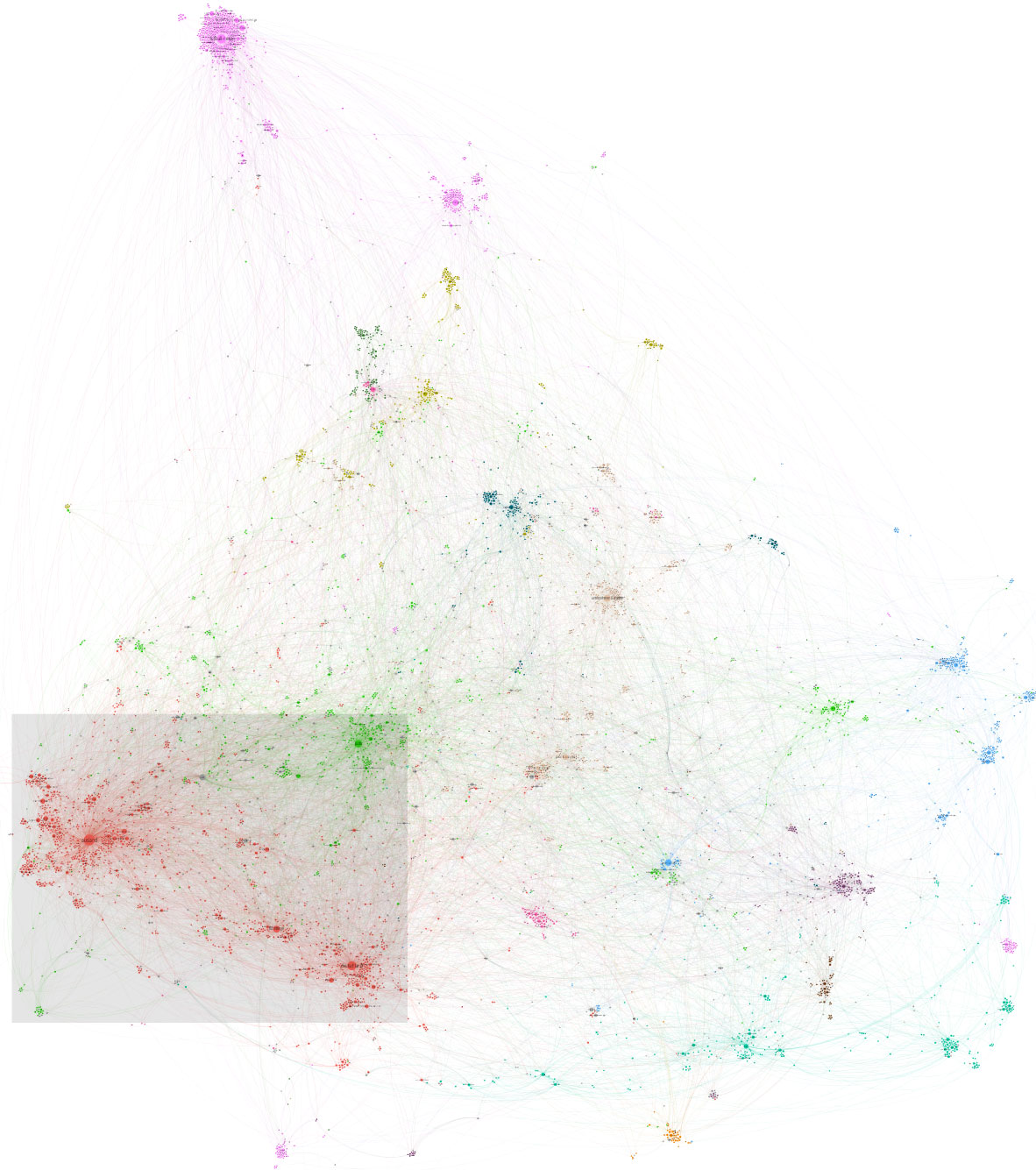
Er ist so groß, dass wir gar nichts erkennen können, ausser verschieden farbigen Landschaften. Ich sorge mal für eine ganz grobe Orientierung. In den unteren zwei Dritteln des Bildes ist der Hauptkontinent der Themen. Oben, etwas losgelöst vom Hauptkontinent, sind die meisten Sportthemen (der lila Knubbel).
Im Hauptkontinent ist rot im Südwesten das Politik-Ressort. Rechts darüber in grellgrün ist das Panoramaressort. An den Grenzen zwischen den beiden Ressort-Bundesländern gibt es eine rot-grüne Mischung.
Die Kette von türkisen Clustern entlang der Unterseite des Hauptkontinentes sind die verschiedenen Teile der Netzwelt. Blau im Osten ist der Kulturteil (der auch einige Inseln in der Mitte hat). Dunkellila im Südosten ist der Karrierespiegel, darunter in Braun der UniSpiegel. Die Ockergelben Punkte im Norden sind die Wissenschaftsthemen.
Wir haben jetzt nicht alle durch, aber ihr habt nun eine grobe Orientierung. Eigentlich wollte ich euch aber durch mehrmaliges Zoomen darstellen, wie riesig die Themenlandkarte ist. Wir zoomen also mal das grau unterlegte Rechteck heran. Hier ist es:
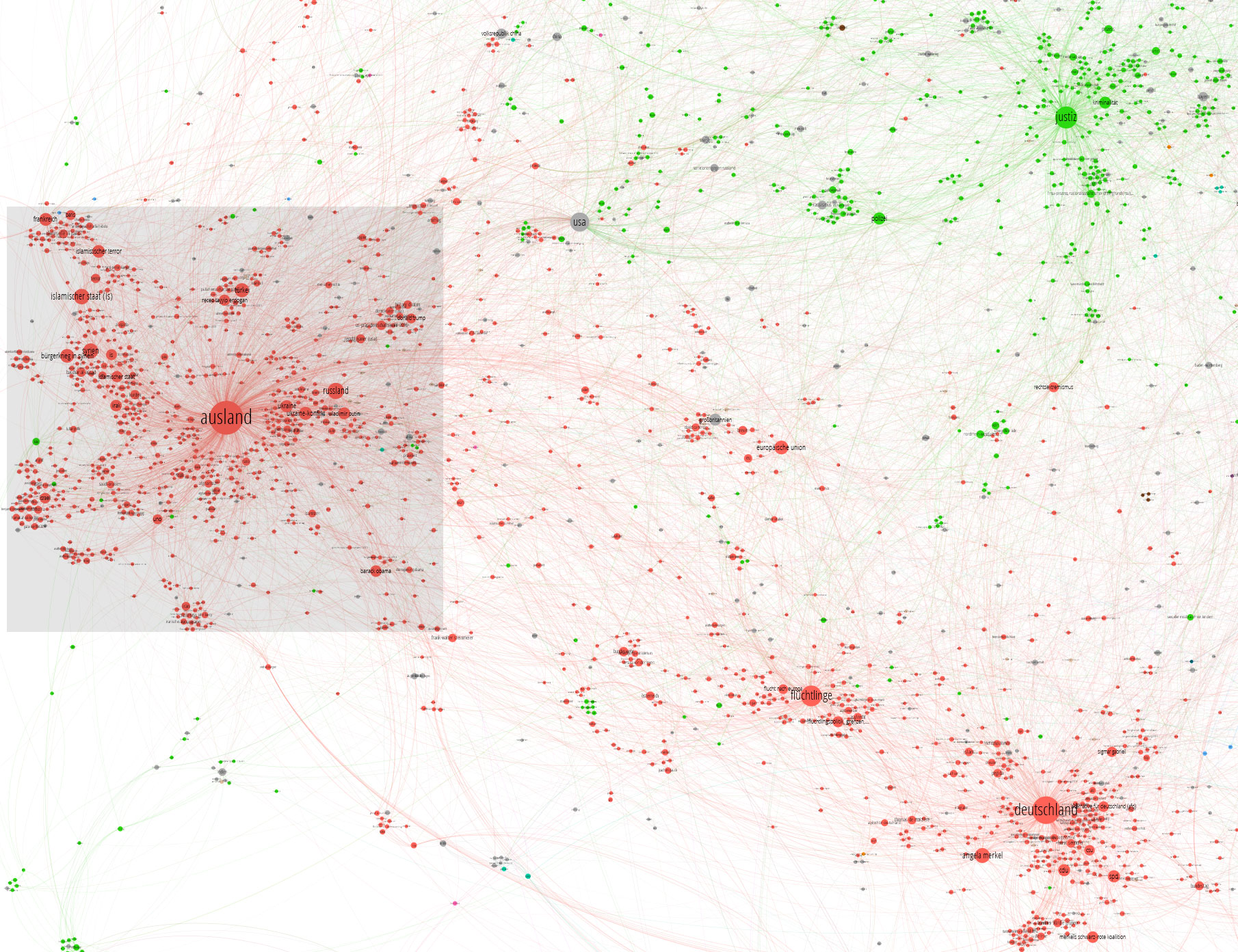
Ihr könnt übrigens jedes der Bilder anklicken, um eine größere Version zu erhalten.
Wir erahnen, dass die Politik von drei großen Zentralgestirnen dominiert wird: „inland“ und „ausland“ (so gut, so erwartbar), und – „flüchtlinge“. Das Thema Flüchtlinge ist dermaßen groß behandelt, dass es einen eigenen großen Cluster bildet. Oben rechts sehen wir, dass „justiz“ im Panorama-Ressort eins der Zentren bildet, das viele andere Themen um sich versammelt. Wir zoomen weiter rein, in die Auslandspolitik (wieder ins unterlegte Rechteck).
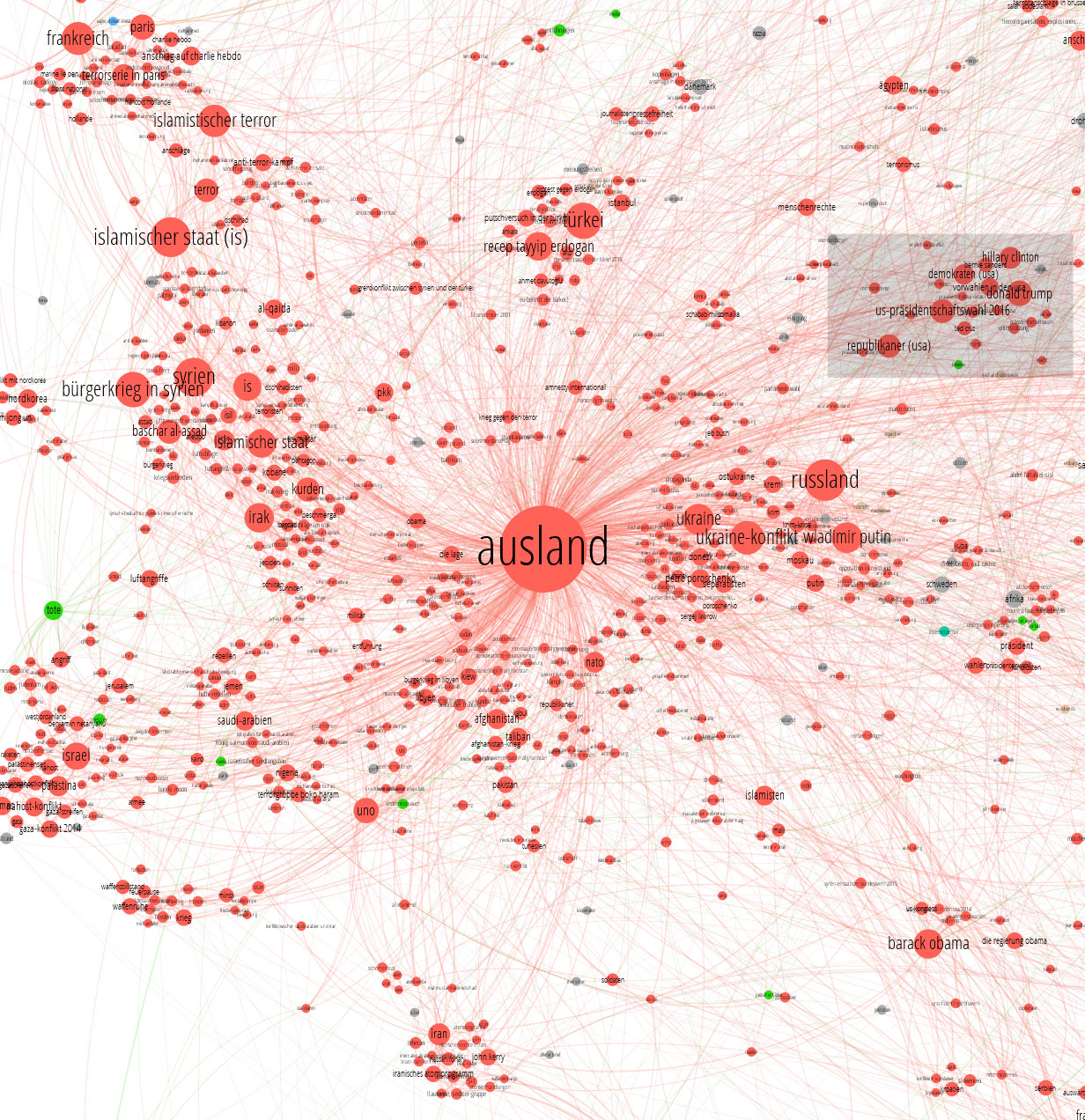
Wir haben jetzt schon so tief reingezoomt, dass wir die größeren Themen der Auslandspolitik erkennen können. Alle sind sie da: Frankreich, nahe am islamischen Terror, in der Nähe davon wiederum der Islamische Staat, daran wiederum nah (vergesst nicht, wir visualisieren verwandte Themen!) der Bürgerkrieg in Syrien und Syrien selbst. Etwas abgegrenzter dann andere Themenkomplexe: Der Ukrainekonflikt, die Türkei, Israel und der Nahostkonflikt, und und und. Ihr seht schon, wie sich verwandte Themenbereiche zusammengefunden haben, oder? Wieder zoomen wir ran, auf die Ebene einzelner Keywords, wieder ins unterlegte Rechteck.
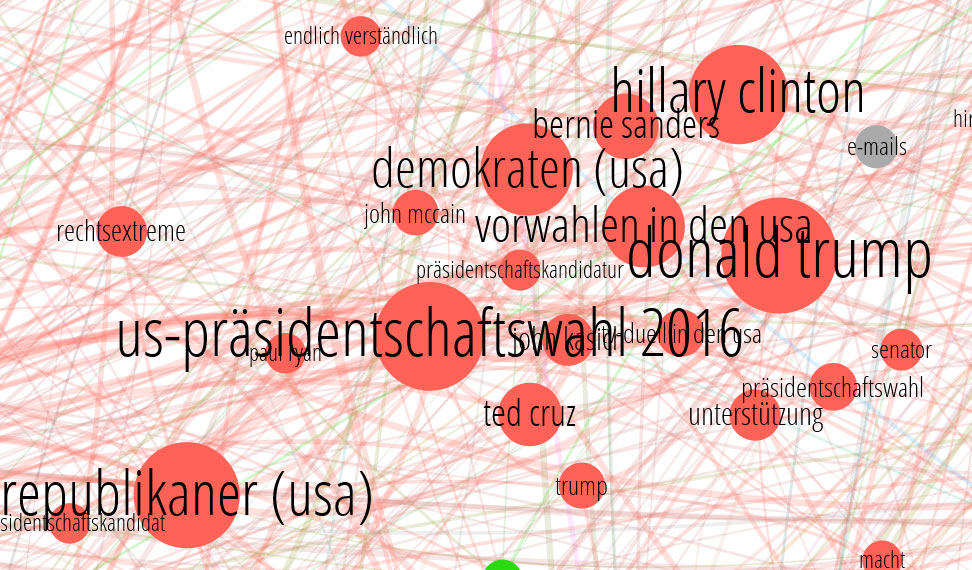
Das ist jetzt das tiefste Level. Hier sieht man den eng umgrenzten Themenkomplex zur US-Wahl 2016 mit den beiden Kandidaten, dem dritten Mitspieler, Bernie Sanders, und den beteiligten Parteien. Ich wiederhole noch mal: Das Layout des Graphen erfolgte allein aufgrund der gemessenen Verwandtschaft der Artikel, das hat sich also alles allein so zusammengefunden und Strukturen gebildet. Im Bild sieht man übrigens auch den Knoten „e-mails“ – in grau. Der scheint sich da wegen Frau Clintons E-Mail-Affäre eingefunden zu haben, obwohl in seinen Artikeln kein Ressort dominiert - darum ist er nicht rot gefärbt, wie seine Nachbarn, in denen das Ressort „Politik“ dominiert. Durch diesen mehrmaligen Zoom solltet ihr jetzt eine ungefähre Vorstellung haben, wie groß die Landkarte überhaupt ist.
Bevor wir nun das erste mal auf Bereiche der Landkarte genauer eingehen und Schlussfolgerungen ziehen, möchte ich euch aber die Gelegenheit zum unvoreingenommenen selbst-spielen geben. In den vorherigen Artikeln habe ich die Landkarten einfach als PDF geliefert. Das geht hier zwar theoretisch auch noch, aber die Landkarte ist so groß, dass diverse PDF-Reader einfach crashen. Also habe ich die Landkarte so aufbereitet, dass ihr nichts runterladen müsst und darin einfach online so herumzoomen und schieben könnt, wie ihr es von z.B. Google Maps gewohnt seid. Für die ganz eiligen gibt es hier eine kleine, in diese Seite eingebettete Version – aber darunter gibt es einen Link auf eine Version, die sich im Vollbild öffnet. Da habt ihr mehr davon – viel Spaß damit, nehmt euch Zeit!
Hier gibt es die Fullscreenversion!
Hier gibt es auch noch die Landkarte als PDF, da könnt ihr sinnvoll Volltextsuche drin machen, wenn ihr ein bestimmtes Thema sucht. Wenn ihr den Ort des Themas dann kennt, könnt ihr mit der Online-Karte dorthin navigieren, weil das deutlich bequemer ist als mit einem PDF. Damit die Karte in den gängigen PDF-Readern nicht unerträglich langsam wird, habe ich die Kanten weggelassen, aber die sind ja in der Online-Version drin.
Techniktipp: Ich empfehle für das Angucken solch umfangreicher PDFs SumatraPDF. Es ist ein kleiner PDF-Reader ohne großen Schnickschnack, der aber so große PDF-Graphen zackig rendert. Vor allem aber funktioniert die Volltextsuche bei solchen Graphiken besser als beim Acrobat Reader. Wer also mit der Suche des Acrobat Probleme hat – bitte Sumatra nehmen!
Verwandte Keywords finden
Wie waren wir eigentlich auf die Thematik gekommen? Ach ja, wir hatten bemerkt, dass es mehrere Keywords zu derselben Sache geben kann, was Messungen des Berichterstattungsvolumens zu bestimmten Thematiken schwer macht. Oben im Artikel hatten wir „germanwings“ und „andreas lubitz“ betrachtet. Wir suchen jetzt mal in unsere Keywordkarte, was sich dazu findet. Und voila:

Siehe da, es gibt sogar ein (Riesen-)Keyword zu der ganzen Angelegenheit, dass wir gar nicht kannten: „germanwings-a320-absturz in südfrankreich“. Mann, was für ein Oschi, wir sollten hier mal goldene Himbeeren für die längsten Keywords verleihen, oder? Wenn wir jetzt alle Artikel zu einem Thema finden wollen, wissen wir, welche Gruppe an Keywords wir suchen müssen. Sehr praktisch.
Was hatten wir noch? Richtig, die AfD. Dazu hatte ich bereits durch scharfes Hingucken die Keywords „afd“ und „alternative für deutschland (afd)“ ausgegraben (auch oben im Artikel). Und siehe da, es gibt zusätzlich noch „alternative für deutschland“ als keyword.

Schauen wir mal, wie die Veröffentlichungsvolumina der drei Keywords im Vergleich so sind:
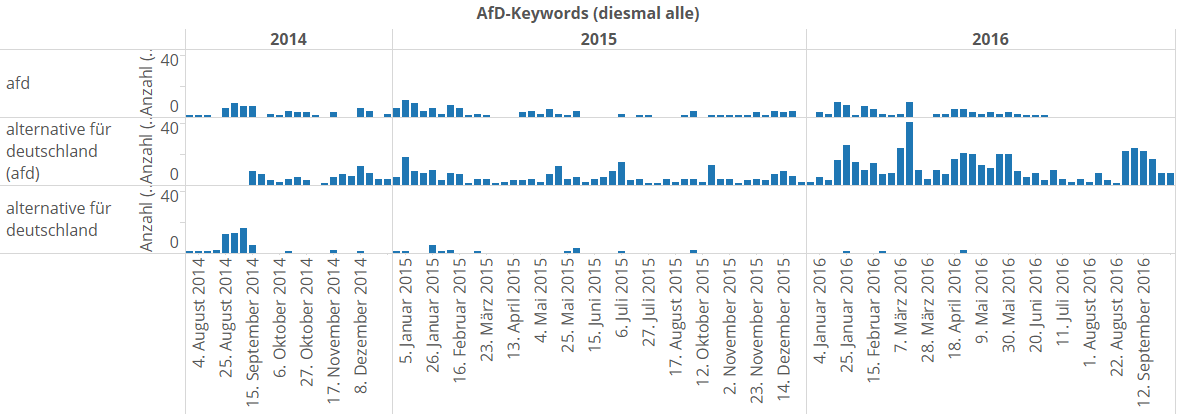
Wir sehen, dass sich „alternative für deutschland (afd)“ gegenüber seinen beiden Keywordgeschwistern insgesamt durchgesetzt hat. „alternative für deutschland“ und „afd“ haben daneben noch relativ lange überlebt, aber am Ende verloren.
Anwendungsbeispiel: Berichterstattungsvolumen nach Parteien
So, und jetzt kommen wir mal zur ersten praktischen Anwendung, die ohne das Finden verwandter Keywords so nicht oder weniger gut funktioniert hätte: Stellt euch mal vor, ihr würdet gefragt, wieviele Artikel es über die verschiedenen Parteien gibt und wie das Berichterstattungsvolumen zu den verschiedenen Parteien über die Zeit so verlaufen ist. Ich bin das neulich gefragt worden. Da könnt ihr nicht einfach nur die Keywords „csu“, „fdp“, „grüne“ und so weiter eingeben und die Artikel zählen, weil es für jede Partei redundante Keywords gibt, und ihr nicht wisst, ob ihr vielleicht eine größere Menge Artikel ausklammert, indem ihr die redundanten Keywords nicht betrachtet. Die Fragestellung klingt also erstmal trivial, ist es aber bei näherer Betrachtung dann plötzlich nicht mehr (übrigens ebenfalls ein Phänomen, was in der DataScience ganz alltäglich ist). Das gefährliche ist, dass der oben skizzierte Lösungsweg, auf den man erstmal kommt, technisch gesehen funktioniert und vielleicht auch plausible Ergebnisse bringt, aber eben trotzdem vielleicht inakkurat ist.
Genauso wie bei der AfD habe ich also mal den Graphen für alle Parteien angeguckt (ich mache hier jetzt absichtlich keine Bilder, damit ihr mal selbst suchen könnt), und redundante Keywords gefunden. Herausgekommen sind folgende (in alphabetischer Ordnung nach Common Name der Partei):
- AfD: afd, alternative für deutschland (afd), alternative für deutschland
- CDU: cdu, union
- CSU: csu (Das Leben ist eben hart, wenn man im Bundestag im Wesentlichen über die große Schwester genannt wird, da gibts dann nicht mehr Keywords)
- Die Grünen: bündnis 90/die grünen, grüne
- Die Linke: die linke, linke, linkspartei
- FDP: fdp, liberale
- Piratenpartei: piraten, piratenpartei (Anekdötchen: Du weisst, dass du als Partei am Arsche des Propheten bist, wenn ein verwandtes Keyword zu deinem Parteinamen „was wurde aus…?“ ist)
- SPD: sozialdemokraten, spd
Ich habe das mal aufgetragen. Erstmal betrachten wir das Berichterstattungsvolumen einer jeden Patei für sich (die Y-Achsen der jeweiligen Parteien sind hier unabhängig skaliert). Das erschwert eine vergleichende Betrachtung, aber macht es einfacher, zu sehen, wo es parteiübergreifend Berichterstattungspeaks gibt.
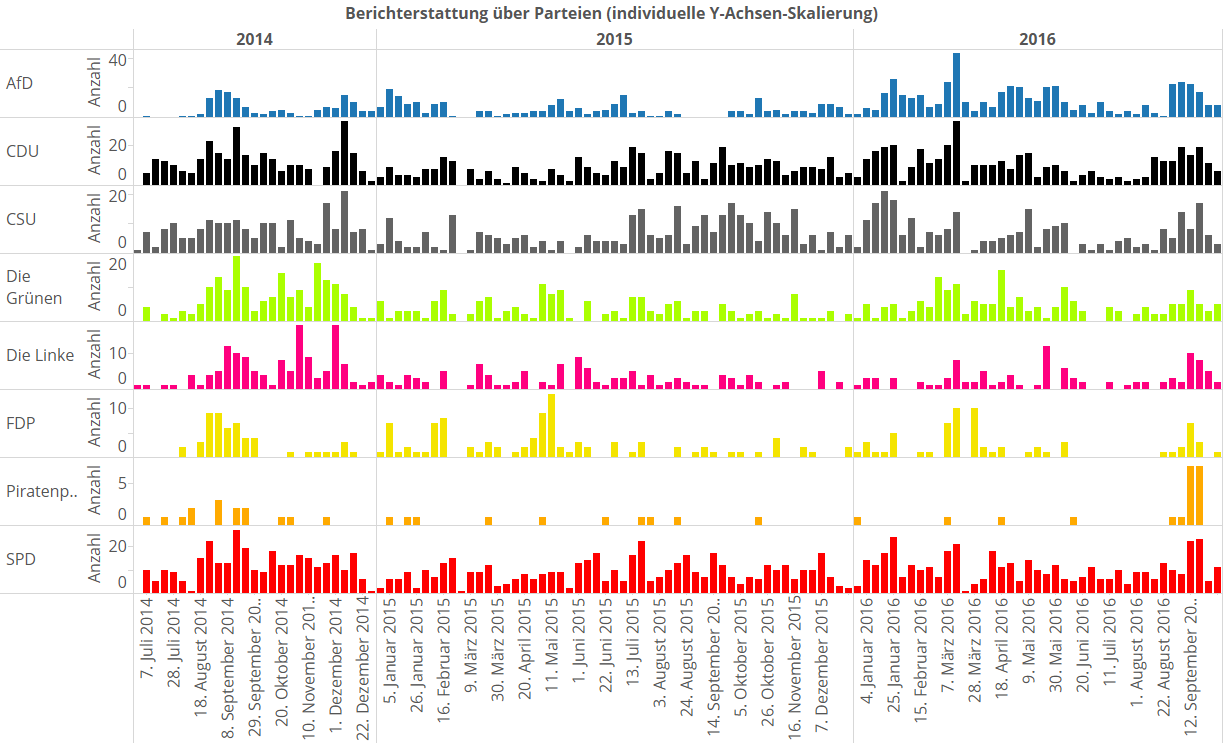
Wir sehen sofort den Peak, den die Landtagswahlen im März über alle Parteien verursachen – samt anschließendem Berichterstattungskater. Jetzt plotten wir mal die Berichterstattungsvolumina der Parteien im Verhältnis zueinander auf:
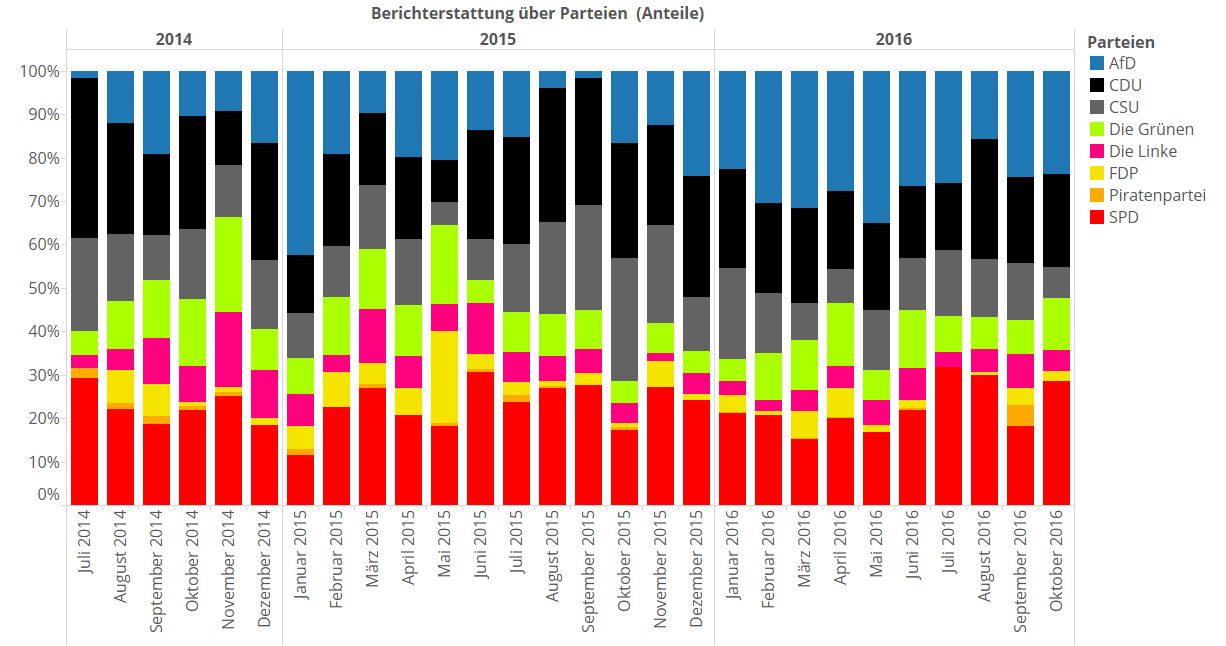
Die Berichterstattungsvolumina der Parteien verhalten sich ungefähr proportional zu deren Wichtigkeit im Bundestag. SPD und CDU sind eher stark vertreten, Grüne so mittel, Linke und FDP eher schwach. Piraten sind töter als tot. Große Ausnahme ist die AfD: Gebt euch das Berichterstattungsvolumen. Die AfD schlägt teilweise die großen, etablierten Parteien, Im zeitlichen Umfeld des Staunens über die Landtagswahlen im März mag das ja erwartbar gewesen sein, aber das Gesamtvolumen überrascht mich dann doch. Auffällig ist, dass das starke Gesamtvolumen der AfD einen krassen Einschnitt im September 2015 hat. Da war glaube ich genau der Start der intensiven Flüchtlingsberichterstattung, oder? Wir vergleichen mal (auch für das Flüchtlingsthema habe ich übrigens mehrere Keywords zusammengesucht, damit ich sinnvoll zählen kann):
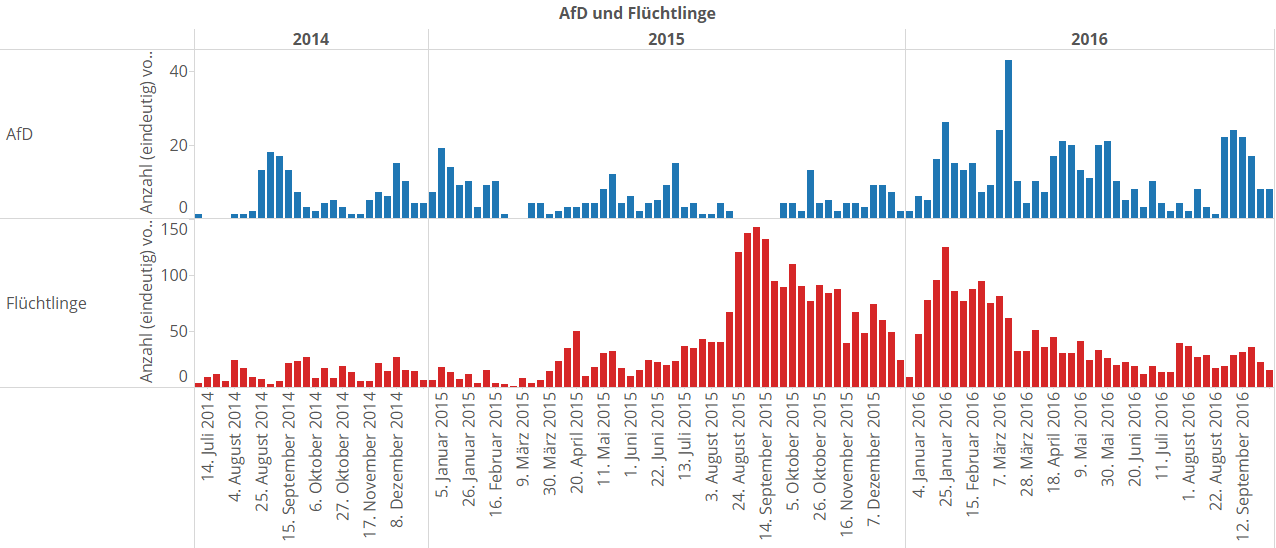
Volltreffer. Als die Flüchtlingsberichterstattung das erste mal so richtig hochkochte, gab es genau zeitgleich ein absolutes Berichterstattungstief bei der AfD. So, und bevor hier jetzt so richtig die Gemüter hochkochen und ich Mails kriege a la „Mimimimi Lügenpresse alles totgeschwiegen mimimimimi“: Vorsicht mit direkten Schlussfolgerungen in der DataScience! Man kann hier für mehrere mögliche Ursachen gute Argumente finden. Die Flüchtlingskrise mag zwar in die absoluten Kernbereiche der AfD-Themen passen, aber das heisst nicht, dass sie auch klug genug waren, das für sich zu benutzen. Erinnert euch an die NSA-Affäre. Das hat die absoluten Kernthemen der Piraten direkt berührt, und diese Schwerstmehrfachbegabten haben da auch nichts auf die Kette gekriegt, sondern sich lieber öffentlich untereinander auf Twitter angefeindet.
Ich gebe aber zu: Das Muster ist hier schon echt auffällig, wenn man noch mal auf den obigen Plot mit den separat voneinander gemessenen Parteiberichterstattungsvolumina guckt – die AfD ist die einzige Partei mit diesem krassen Abfall. Interessant. Wir gehen jetzt aber noch mal zum eigentlichen Thema zurück – der riesigen Landkarte.
Der Graph wird uns noch wiederbegegnen
Ich kann es nicht oft genug erwähnen, dass es nur eine Breitbandverbindung zum Gehirn gibt: Die Augen. Wir haben nun erforscht, wie wir eine Landkarte erzeugen können, in der sich verwandte Themen zusammenfinden. Das an sich ist ja schon interessant und schön zu erforschen – wir haben aber noch gar nicht darüber geredet, wie mächtig so ein Graph ist, um ganz verschiedene Informationen rüberzubringen.
Bis jetzt haben wir die Daten nur nach sehr einfachen Merkmalen auseinandergeteilt und über Teilmengen dann irgendwas gemessen. Beispielsweise: Wir haben die Daten anhand Erscheinungswochentag und Erscheinungsstunde in Töpfe geteilt und die durchschnittlichen Wortanzahlen pro Topf gemessen. Wir hatten bis jetzt kaum eine Chance, Töpfe anhand ganzer Themenkomplexe zu bilden, um vielleicht Zusammenhänge zu entdecken, die nicht mit einfach klassifizierbaren Größen, sondern mit dem tatsächlichen Inhalt eines Artikels zusammenhängen.
Genau das haben wir nun möglich gemacht.
Seht jeden einzelnen Knoten im Graph als einen solchen Topf, genau wie die Tage-Stunden-Töpfe das vorher waren. Über die darin enthaltenen Artikel kann man genauso Sachen messen und dann die Knoten danach einfärben oder deren Größe danach richten. Das mächtige daran ist, dass die Position der Töpfe bzw. Knoten zueinander jetzt auch enorm etwas aussagt. Sehen wir also beim Einfärben des Graphen irgendein System, zum Beispiel ähnlichfarbige Landstriche, haben wir einen Zusammenhang des gemessenen Wertes zum Thema gefunden.
Der Graph ist also nicht nur eine nette Landkarte, um mal zu sehen, welche Themen verwandt sind – er ist ein extrem mächtiges, allgemeines Visualisierungswerkzeug. Angenommen wir färben mal wieder alle Knoten nach Textlänge ein – vielleicht gibt es ja einzelne Landstriche und Regionen, in denen sich nur Themen mit kurzen Texten befinden. Solche Zusammenhänge sind von nun an direkt sichtbar, und in den folgenden Artikeln werde ich auf dieses sehr mächtige Werkzeug noch zurückgreifen.
Ein kleines Beispiel anhand des Graphens, den wir hier haben: Wir haben die Knoten ja nach dem innerhalb des Knotens dominierenden Ressort eingefärbt. Hier ist der Themenkomplex zur Griechenland-Krise:
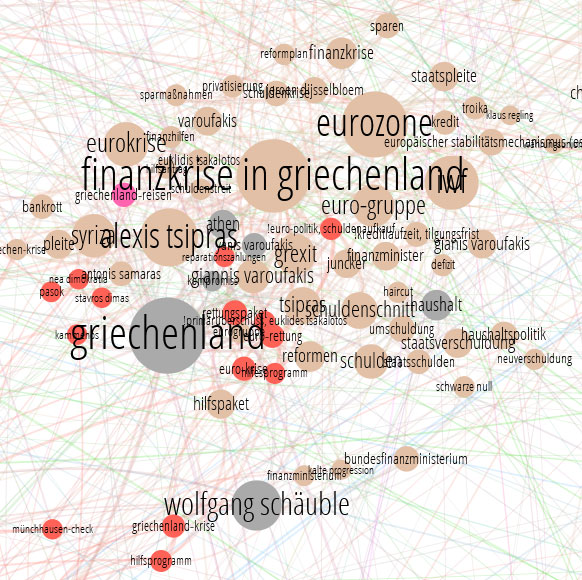
Der ist im Wesentlichen in den Farben des Wirtschafts- und Politikressorts. Die Griechenkrise ist also ein Themenkomplex zwischen Wirtschaft und Politik. Stimmt.
Liebe Leser ...
… nun bleibt mir nur, für heute wieder ein schönes, rheinisches „Tschö“ zu sagen.
DIeser Artikel und der letzte waren für mich übrigens die bis jetzt langwierigsten. In den ersten drei Artikeln haben wir sofort kleine, sehr konkrete Untersuchungen durchgeführt und konnten uns dann von Ergebnis zu Ergebnis weiterhangeln, so dass es mir möglich war, euch jeweils auf eine bildhafte Entdeckungsreise mitzunehmen.
In diesem und dem letzten Artikel ging das so nicht. Hier haben wir etwas Allgemeines erschaffen, Das wird uns in weiteren Artikeln extrem viel bringen und diese enorm aufwerten – aber während der Erschaffung hat es eben keine Zwischenergebnisse geliefert, an denen wir uns gemeinsam entlanghangeln konnten. Also musste ich die beiden Artikel von der didaktik her komplett anders schreiben – die Zusammenhänge sind ja gar nicht sooo unkompliziert und ich wollte gerne, dass ihr auch ohne konkrete Ergebnisse dran bleibt.
Der vorliegende Artikel war übrigens auch technisch der aufwändigste. Lasst euch nicht weismachen, dass irgendjemand im ersten Versuch so einen Graphen samt Mathematik und Entwicklung dahinter in einem halben Tag programmiert. Dann fühlt ihr euch nur entmutigt und verliert das Interesse an der DataScience. Auch Profis brauchen gerne mal Wochen an Gedanken und Entwicklung, bis so was durchdacht ist, entwickelt ist, funktioniert und schließlich auch noch gut aussieht.
Ich hoffe, das Ergebnis sagt euch zu – und ihr bleibt mir gewogen.