Inhaltsverzeichnis
Xerox-Scankopierer verändern geschriebene Zahlen
Vorabanmerkungen:
- Eine (lange nicht erschöpfende) Presseschau habe ich anlässlich meiner Gastvorlesung zum Thema hier zusammengestellt. Ich bin selbst überrascht, wie viele Artikel es gibt.
- Eine Zeitleiste der ganzen Angelegenheit gibt es weiter unten. Darin kann man sich einen Überblick verschaffen, und findet auch die relevanten Blogartikel verlinkt. Daraus geht auch klar hervor, dass ich Xerox sehr viel Zeit gelassen habe, also nicht einfach mit der Sache an die Öffentlichkeit gegangen bin. Das ist mir wichtig, weil ich erstmal versuche, im nicht-öffentlich auf Leute zuzugehen, wenn ich etwas zu beanstanden habe.
Video und Folien zu meinem Vortrag "Traue keinem Scan, den du nicht selbst gefälscht hast" (31C3)
Hier gibt es auch noch die Vortragsfolien.
Hier könnt ihr mir Feedback über den Vortrag geben! Das ist mir wichtig, danke!  (Achtung: 5 ist das beste, 1 ist das schlechteste, das sind keine Schulnoten.)
(Achtung: 5 ist das beste, 1 ist das schlechteste, das sind keine Schulnoten.)
Einleitung
In diesem Artikel dokumentiere ich ausführlich, wie weit verbreitete Firmen-Scankopierer der Firma Xerox bei gescannten Seiten Ziffern, Zahlenreihen oder andere Bildfragmente unvorhersehbar vertauschen/ersetzen – und zwar nicht aufgrund irgendwelcher Texterkennung, sondern richtig hart in den Pixeldaten. Das Ergebnis sind Dokumente, die subtil falsch sind, aber perfekt aussehen – so, dass man es auf den ersten Blick nicht bemerkt. So etwas kann extrem gefährlich sein oder sogar Menschenleben kosten. Der Phantasie sind keine Grenzen gesetzt:
- Abrechnungen, die plötzlich nicht mehr stimmen.
- Baupläne mit vertauschten Quadratmeterzahlen.
- Falsche Ingenieurspläne, die wiederum Menschenleben gefährden würden (stellt euch vor, eine Autobahnbrücke hat in der Statik einen Zahlendreher verbaut).
- Arzneimitteldosierungen mit Zahlendrehern, eigentlich noch schlimmer.
Ihr seht schon: Was sich zunächst locker anhört, ist absolut kritisch und kann schnell lebensgefährlich werden. Es handelt sich um einen acht (!) Jahre alten Bug, der nach Händlerinformationen hunderttausende Xerox-Multifunktionskopierer weltweit betrifft. Mehrere große Gerätefamilien sind betroffen (eine Liste gibt es weiter unten). Jeder, der diese in den letzten acht Jahren eingesetzt hat oder jetzt noch einsetzt, muss sich fragen:
- Wieviele fehlerhafte Unterlagen, die auf den ersten Blick richtig aussehen, habe ich in den letzten Jahren gespeichert oder gar an dritte herausgegeben?
- Sind durch diese denkbaren Fehler Menschen oder Vermögenswerte gefährdet?
- Kann ich für diese Fehler verantwortlich gemacht werden?
Bis zur Behandlung des Fehlers in meinem Blog war er nicht entdeckt oder veröffentlicht. Seine Tragweite entfaltete sich auch erst in Laufe meiner verschiedenen Blogartikel, die von den Massenmedien aufgegriffen und verbreitet wurden. In welcher Reihenfolge was geschah, lässt sich anhand der nachfolgenden Zeitleiste sehen. Es waren zwei interessante Wochen, das kann ich euch versprechen.
Der Rest des Artikels ist wie folgt gegliedert.
- Es wird an einer Zeitleiste beschrieben, wie die Angelegenheit sich entfaltet hat
- Es wird an konkreten Beispielen beschrieben, wie der Fehler entdeckt wurde, und wie subtil er auftritt. Weil schwer zu glauben ist, dass ein Scankopierer Zahlen verdreht, liefere ich natürlich Beweismaterial mit.
- Danach kommt eine Liste der betroffenen Kopierer.
- Es folgt eine grobe Anleitung, wie sich der Fehler reproduzieren lässt.
- Zuletzt gibt es eine kurze, laienhafte rechtliche Würdigung der rechtlichen Folgen. Kurzform: Die letzten 8 Jahre an PDF-Scans von betroffenen Geräten kann nicht nur Fehler enthalten, sie sind anscheinend auch rechtlich komplett wertlos, und zwar unabhängig davon, ob Fehler tatsächlich nachgewiesen werden.
Kurze Zeitleiste, was wann geschah
Ich werde immer wieder gefragt, ob es eine Kurzzusammenfassung gibt, was in welcher Reihenfolge geschah – hier ist sie. Die relevanten meiner Blogartikel sind verlinkt (teilweise schlecht sichtbar, aber die Links sind da). Die Liste wird ggfs. aktualisiert, der aktuelle Status ist immer mit einem  markiert.
markiert.
| Datum | Was geschah |
|---|---|
| 24. Juli 2013 | Nummernvertauschen entdeckt |
| 25. Juli | Xerox das erste mal Bescheid gesagt dass Buchstaben vertauscht werden. In den nächsten Tagen wusste der Xerox-Support über mehrere Level hinweg nicht, woher das kommen könnte. Mitarbeiter eines Xerox Helpdesks vor Ort haben sich angestrengt, den „Fehler“ bei sich zu reproduzieren – erfolgreich. Ich finde das wichtig, weil es darstellt, dass ich mich nicht sofort aufmerksamkeitssuchend ans Internet gewendet habe, sondern erst einmal an Xerox. Später sollte ich noch erfahren, dass das Problem durchaus bei Xerox bekannt ist. |
| 1. August | Bis jetzt keine Hilfe von Xerox, fast eine Woche, über alle Ebenen des Supports hinweg. Alle schauen nur erstaunt. Ich finde das beängstigend und schreibe diesen Blogartikel. |
| 2. August | Der Artikel schlägt ein. Ich erhalte Mails von Leuten, die den „Fehler“ reproduzieren können sowie Informationen zur JBIG2-Kompression, die ich in meinen Artikel einpflege. |
| 6. August, morgens | Von einem Leser kriege ich Infos, dass es im Adminpanel der Kopierer eine winzige Meldung über Character substition gibt und der Fehler weg sei, wenn man die Kompression von „normal“ auf „higher“ schickt. Mir wird klar, dass das ganze bei Xerox ja wohl bekannt sein muss, wenn es da eine Meldung gibt. Das Problem bleibt: Leute können unwissentlich subtil falsche Dokumente produzieren, da die Meldung nur beim Setzen der Kompressionseinstellung angezeigt wird. Ich präsentiere dennoch einen Workaroundartikel. |
| 6. August, nachmittags | Telefonkonferenz mit Rick Dastin und Francis Tse. Rick Dastin, Vizepräsident bei Xerox, ist der erste Xerox-Angestellte, der mir sagt, dass Zahlen vertauscht werden können – aber auch, dass das gewollt ist. Ich kritisiere, dass der fragliche Kompressionsmodus „normal“ heißt. Ich lerne, dass auch in den gängigen Anleitungen zu Xeroxkopierern zwei kleine Anmerkungen über Character Substitution drin sind (inmitten von ca. 300 Seiten). Beide Anmerkungen beziehen sich ebenfalls auf die Kompression „normal“. Mir wird versichert, dass „normal“ entgegen der Intuition nicht die Fabrikeinstellung ist. |
| während der Telefonkonferenz | Xerox veröffentlicht erstes Pressestatement. „For data integrity purposes, we recommend the use of the factory defaults with a quality level set to “higher.”“ Sie sagen außerdem, dass es den besagten Hinweis über Character Substitition gibt und bestätigen den Work Around aus meinem Blog. |
| 7. August | Zweites Statement, Softwarepatch wird angekündigt, liest sich so als würde der „normal“ mode damit eliminiert werden. Xerox sagt klar: „You will not see a character substitution issue when scanning with the factory default settings.“ In einem weiteren Document werden die factory Defaults definiert: Kompression „higher“, mindestens 200 DPI. |
| 9. August | Es gelingt mir, mit Kompression „higher“ und sogar 300 DPI Nummernvertauschungen zu erzeugen. Ich rufe zunächst Xerox an, warte, bis sie unter den gleichen Einstellungen vertauschte Zahlen sehen, und veröffentliche danach in Zusammenarbeit mit Xerox einen ausführlichen, warnenden Blogartikel, da nun hunderttausende Geräte in den Fabrikeinstellungen betroffen sind. |
| 11. August | Auf einem Xerox WorkCentre 7545 scheinen sogar alle drei Kompressionsmodi betroffen, also auch der höchste. Ein Leser berichtet das gleiche vom 7655. Völlig kompressionsunabhängig werden Zahlen und Buchstaben im Bild vertauscht, wobei der Effekt geringer wird, aber nicht verschwindet, wenn man die Qualität höherschraubt.Blog-Artikel hier. |
| August 12 | Xerox bestätigt mir einen Software-Bug, der tatsächlich alle Kompressionsmodi umfasst und kündigt einen Patch an. Es können tatsächlich über alle Kompressionsmodi hinweg Zahlen vertauscht werden – und das seit acht Jahren! *uff* Dann gehe ich ja doch nicht in die Geschichte ein als der Typ, der zu doof war, die Anleitung zu lesen.  Hier ist ihr Pressestatement. Hier ist ihr Pressestatement. |
| August 19 | Ich habe heute das Xerox-Softwareupdate vorab getestet. Sieht gut aus. Sie haben das Pattern Matching komplett eliminiert. Leider bestätigen mir heute diverse Xeroxvertriebler, dass die Zahl der Geräte tatsächlich in die Hunderttausende geht. |
| August 22 | Die ersten Patches werden von Xerox released. Aufgrund der großen betroffenen Geräteanzahl werden die Patches in mehreren Wellen released werden. |
| Sept 11 | Da ich immer mehr gefragt werde, warum ich von Xerox kein Geld verlangt habe: Dafür gibt es klare Gründe. Klickt hier für einen Blogartikel darüber. |
| Ab da | Da Xerox einen dezentralen Vertrieb hat, können sie ihre Kunden nicht einfach auflisten und erreichen. Daher ist es komplett unklar, wieviele Geräte gepatched wurden. Ich würde denken, dass noch hunderttausende ungepatchte Geräte im Feld stehen. Also: Spread the word. |
| März 2015 | Das Bundesamt für Sicherheit in der Informationstechnik rät in seiner technischen Richtlinie RESISCAN von der Verwendung von JBIG2 ab. |
Fallbeispiele und Entdeckung des Fehlers
Das erste mal aufgefallen ist dem betroffenen Unternehmen der Fehler am vergangenen Mittwoch, als ein Bauplan zu einem PDF gescannt und wieder gedruckt wurde. Baupläne enthalten für jeden Raum des zu bauenden Hauses Boxen mit Quadratmeterzahlen, die irgendwie in den betreffenden Raum hineinlayoutet sind. In einigen Räumen standen nun sauber layoutete, jedoch schlicht falsche Quadratmeterzahlen – man muss wirklich die Zahlen lesen, um den Fehler zu bemerken. Der Fehler ist nur entdeckt worden, weil man hier nicht tatsächlich die Originalzahlen auswendig kennen musste, sondern es hat sich einfach jemand gewundert, warum ein Raum mit angeblich 14 Quadratmetern deutlich größer ist, als der danebenliegende 22-Quadratmeter-Raum.
Vorab hier eine Komplettansicht der Originalversion der betroffenen Seite – zu den Unterschieden kommen wir danach. Ich musste die Seite natürlich teilweise schwärzen. Klickt zum vergrößern drauf. Die gelben Markierungen habe ich zugefügt, das werden meine Beispielfehlerstellen sein. Achtet auf die Quadratmeterzahlen in den Boxen – diese sind mies aufgelöst, aber lesbar. Ich nummeriere sie für spätere Nennung durch, sei die obere „Stelle 1“, die untere linke „Stelle 2“ und die untere rechte „Stelle 3“.
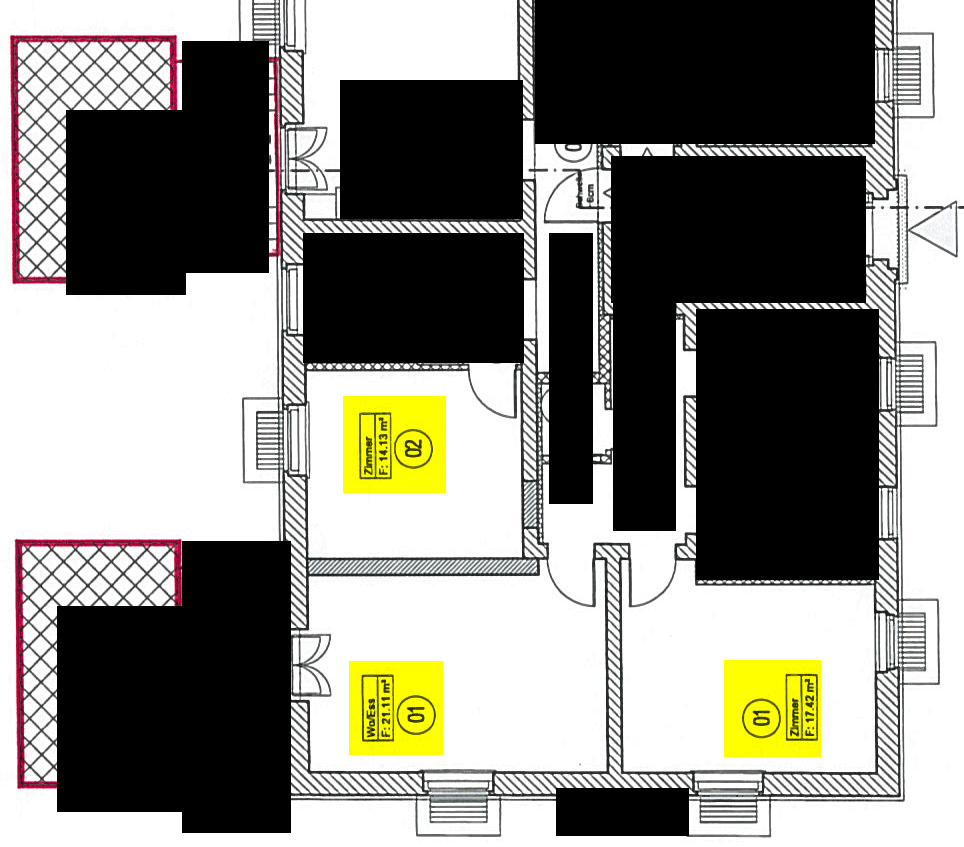
Jetzt scannen wir den Bauplan auf dem Scankopierer als PDF ein. Ohne Texterkennung oder sonstige Späße. Dann stehen an den drei Stellen andere Nummernwerte  . Ich liefere Screenshots der drei Stellen in den PDFs als Tabelle. Die Originale sind zur direkten Vergleichbarkeit in einer Zusatztabellenzeile eingeblendet. Das Xerox WorkCentre 7535 produzierte immer dieselben Fehler, weswegen hier nur eine Tabellenzeile notwendig ist; das WorkCentre 7556 produzierte immer andere Fehler, hier sind einfach zur Demonstration drei Durchläufe abgebildet:
. Ich liefere Screenshots der drei Stellen in den PDFs als Tabelle. Die Originale sind zur direkten Vergleichbarkeit in einer Zusatztabellenzeile eingeblendet. Das Xerox WorkCentre 7535 produzierte immer dieselben Fehler, weswegen hier nur eine Tabellenzeile notwendig ist; das WorkCentre 7556 produzierte immer andere Fehler, hier sind einfach zur Demonstration drei Durchläufe abgebildet:
| Durchlauf / Gerät | Stelle 1 | Stelle 2 | Stelle 3 |
|---|---|---|---|
| Original, aus einem Tif-Scan entnommen, Korrektheit verifiziert |  | 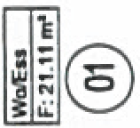 | 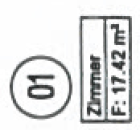 |
| Xerox WorkCentre 7535 |  |  |  |
| Xerox WorkCentre 7556, Durchlauf 1 |  |  |  |
| Xerox WorkCentre 7556, Durchlauf 2 |  |  |  |
| Xerox WorkCentre 7556, Durchlauf 3 |  |  |  |
Die Auflösung ist gering, aber die Zahlen sind deutlich lesbar. Zudem werden hier offensichtlich ganze Bild-Patches vertauscht und/oder mehrfach verwendet. Ich wiederhole, dass das kein OCR-Problem ist, oder zumindest haben wir OCR extra ausgeschaltet, und man sieht ja auch ganz deutlich, wie Pixeldaten durch die Gegend kopiert wurden. Man kann auch nicht einfach sagen „ja, dann nutzt doch eine andere DPI-Zahl“, weil das auch nicht ausschließt, dass irgendwo Bilddaten durcheinandergewürfelt werden.
Nächstes Beispiel: Ein Kostenregister auf dem WorkCentre 7535. Auch hier wieder ein plausibel aussehender Scan, aber bei näherem Hinsehen fällt ein Zahlenfehler auf. In diesem Fall wurde er gefunden, weil Zahlen in Kostenregistern aufsteigend sortiert sind:
| Vorher | Nachher |
|---|---|
 |  |
Man beachte, wie aus der 65 eine 85 geworden ist (zweite Spalte, dritte Zeile). Edit: Ich werde gerade darauf hingewiesen, dass oben rechts auch noch aus einer 60 eine 80 geworden ist. Das ist auch nicht einfach ein Pixelfehler, man kann ganz deutlich sehen, wie die 8 im unterschied zur 6 auf der linken Seite die charakteristische mittige Einbeulung hat. Der Scan war schon mehrere Wochen alt zum Zeitpunkt des Entdeckens, der Fehler ist also auch nicht erst eben aufgetreten. Wer weiß, wieviele Unterlagen schon subtil falsch sind.
Betroffene Geräte
Als die Sache sich noch entfaltete, habe ich in diesem Abschnitt eine „Hörensagen-Liste betroffener Geräte“ anhand Mails von Lesern aufgebaut. Da der Bug mittlerweile von Xerox bestätigt ist, ist die folgende Liste nun keine Hörensagen-Liste mehr, sondern offiziell. Der Buchstabe x kann für beliebige Ziffern stehen, hier sind ganze Gerätefamilien betroffen:
| WorkCentre-Reihe | 232, 238, 245, 255, 265, 275, 5030, 5050, 51xx, 56xx, 57xx, 58xx, 6400, 7220, 7225, 75xx, 76xx, 77xx, 78xx |
|---|---|
| WorkCentre Bookmark-Reihe | 40, 55 |
| WorkCentre Pro-Reihe | 232, 238, 245, 255, 265, 275 |
| ColorQube-Reihe | 8700, 8900, 92xx, 93xx |
Fehler selbst reproduzieren
Nach dem Kostenregister habe ich nach einem Weg gesucht, den Fehler zu reproduzieren. Der Weg ist naheliegend: Zahlenkolonnen generieren, drucken, scannen, OCR drüberjagen und mit der Ausgangszahlenkolonne vergleichen. Da das OCR auch selbst Fehler machen kann, muss man die gefundenen Stellen natürlich noch mal von Hand überprüfen. Die Schriftart für die ich den Fehler hier reproduzieren konnte, war Arial 7pt, mit den Scaneinstellungen wie oben und der neueren Softwareversion des 7535er Workcentres. Und siehe da, aus 6en werden wieder 8en (Beispiele gelb markiert, nicht erschöpfend):
| Vorher | Nachher |
|---|---|
 |  |
Man beachte, wie die 6en drumrum korrekt aussehen und die falschen 8en wieder die charakteristische 8-Eindellung erhalten, es sind also nicht nur einfach wieder irgendwelche falschen Pixel, sondern ausgetauschte Ziffern. Es ist also nicht die Originaldatei (wenn auch die Bilder darin die Originalpixel sind).
Falls ihr mal selbst gucken wollt:
- Hier ist ein Tif-Scan der Seite, fehlerfrei. DEN KÖNNT IHR DRUCKEN UND ALS TESTDOKUMENT NUTZEN. Dass der dann schon mal gescannt und gedruckt ist, ist gewollt – das verrauscht die ziffern leicht, sie sind aber noch gut lesbar. So tritt der Fehler häufiger auf, so dass ihr besser sehen könnt ob ihr betroffen seid.
- Hier ein PDF-Scan mit ein paar für euch vormarkierten falschen Achten auf dem 7535er. Das OCR habe ich nachträglich gemacht, um die Ziffern sauber markieren zu können.
- Auf vielfachen Wunsch: Der gesamte PDF-Scan ohne jegliches Postprocessing meinerseits. Einfach so, wie er aus dem 7535er herausgekommen ist. Viele Seiten.
Ursache und rechtliche Folgen
Der Fehler tritt auf, weil Bildbestandteile, die der Kopierer für gleich hält, nur einmal gespeichert und dann immer wieder verwendet werden. Irrt sich das Ähnlichkeitsmeßverfahren (Pattern Matching) der kopierer, werden eben Zeichenblöcke durch andere ersetzt, zum Beispiel eine 6 durch eine 8. Anders als von Xerox im Rahmen der – verständlichen – PR-Bemührungen suggeriert, tritt der Fehler nicht nur bei schwer lesbaren Ziffern auf (7pt-Schrift auf 300 DPI würde wohl kaum jemand als schwer lesbar bezeichnen), auch wenn die Zeichen relativ klein sind.
Es ist wichtig zu beachten, dass das in den betroffenen PDFs benutzte JBIG2 ein Bildformat ist, und kein Kompressionsalgorithmus, also eine Vorschrift, wie die Kompression eines Bildes an sich erfolgen soll, es definiert nur, wie es danach gespeichert werden soll. Es ist also sozusagen eine Dekompressionsvorschrift, während die kompressionsweise flexibel ist. JBIG2 wurde eigens entwickelt, um effizient Bilder zu speichern, die gescannten Text enthalten. Dafür wird es auch üblicherweise benutzt und so haben sich auch einige übliche Vorgehensweisen der Kompression etabliert, die wir uns in den folgenden Absätzen ansehen können, ohne den Sourcecode von Xeroxmaschinen oder denen anderer Hersteller zu kennen. Insbesondere kann, wie wir gleich sehen werden, das Komprimieren verlustbehaftet und verlustfrei erfolgen. Also bedeutet die folgend beschriebene Fehlerursache, dass nicht JBIG2 der Grund für die bei Xerox aufgetretenen Verfälschungen ist, sondern fehlerhafte Parametrierung beim Kodieren in JBIG2. Der Fehler liegt nicht in JBIG2 selbst. Es wurden durch einen Bug Verluste eingebaut, wo keine hätten sein dürfen.
„Pattern Matching & Substitution“ (PM&S) ist eine der Standardvorgehensweisen bei lossy JBIG2, und „Soft Pattern Matching“ (SPM) die bei lossless JBIG2 (Infos hier oder in den Veröffentlichungen von Paul Howard et al.1)). Im JBIG2-Standard heißt das ganze „Symbol Matching“.
PM&S ist verlustbehaftet, SPM verlustfrei. Beide Kompressionsmodi von JBIG2 arbeiten zunächst nach dem gleichen Schema: Das Bild wird in Symbole zerlegt, diese werden nach Ähnlichkeit gruppiert. Für jede Gruppe werden dann nur Repräsentanten gespeichert und diese wiederverwendet. Im Unterschied zu PM&S werden bei SPM aber die so entstandenen Pixelfehler korrigiert, indem ein Differenzbild zum Original dazugespeichert wird. Dieser Korrekturschritt scheint bei Xerox weggelassen worden zu sein.
Da nun für die PDFs, die mit den Geräten in den letzten 8 Jahren erzeugt wurden, nicht mehr nachgewiesen werden kann, was eigentlich auf dem Blatt Papier stand, dürfte der rechtliche Wert aller dieser gescannten PDFs gegen null gehen! Das bedeutet, dass es eigentlich egal ist, ob tatsächlich Fehler auftreten – bei keinem PDF, wo ganze Bildsegmente wiederverwendet werden, kann der Originalinhalt noch nachgewiesen werden.
Ist Ihr Unternehmen vom Xerox Scanning-Bug betroffen?
Bei mir melden sich gerade immer mehr namhafte Unternehmen, die sich fragen, ob sie erhebliche Probleme haben, jedoch Angst vor Publicity verspüren. Manche sind sich auch schon sicher, dass sie Probleme haben, teils in sicherheitskritischen Tätigkeitsfeldern. Betroffene Unternehmen haben in der Regel drei Ziele:
- Sie wollen das Problem lösen, nach Möglichkeit rückwirkend
- Sie wollen keine Publicity, bei vielen Angestellten nach Möglichkeit nicht einmal intern
- Sie wollen eligible für Schadenersatz bleiben, müssen also aufpassen, nicht im Überschwang Beweismittel für die Fehlfunktion zu vernichten.
Diese Ziele widersprechen teilweise einander; auch große Unternehmen sind nicht gefeit vor Anfängerfehlern. Darum pauschal: Jeder, der sich bei mir meldet, um überhaupt erst einmal die Lage einzuschätzen, kann sich darauf verlassen, dass ich seine Identität nicht preisgebe. Das habe ich über die ganze Angelegenheit so gehandhabt, und damit höre ich jetzt auch nicht auf. Kontaktdaten stehen im Impressum.