
![]()
SpiegelMining: Rubriken, Unterrubriken, Themen, Keywords. Wie SpiegelOnline seine Artikel verdrahtet
Willkommen zu unserer vierten Runde SpiegelMining! Heute fangen wir an, uns der tatsächlichen, inhaltlichen Thematik der Artikel zu nähern. Wir werden gleich mehrere neue Merkmale aus den Artikeln erfassen. Damit werden wir erforschen, wie SpiegelOnline seine Artikel thematisch einordnet. Wir werden sehen, dass SpiegelOnline mehrere Arten der thematischen Sortierung hat.
In den letzten Artikeln hatten wir ja schon einiges an Aufbauarbeit geleistet und verschiedene Artikel-Merkmale betrachtet. Im ersten Artikel gab es eine Betrachtung von Rubriken, Veröffentlichungszeitpunkten und Textlängen. Im zweiten Artikel haben wir die beteiligten Autoren und Nachrichtenagenturen hinzugenommen und gelernt, wie man Beziehungen unter den Autoren visualisieren kann. Wir hatten uns beim Parsen darüber geärgert, dass die in den Artikeln nicht immer an der gleichen Stelle standen. Im dritten Artikel haben wir dann gemerkt, dass die verschiedenen Plätze, an denen die Autoren in den Artikeln stehen können, ein Ausdruck vom Zweiklassensystem der Artikel bei SpiegelOnline sind.
Die thematische Betrachtung, die wir heute anfangen, wird stark über die reine Betrachtung neuer Merkmale hinausgehen. Ich versuche ja neben den Spiegelforschungen immer, euch ein wenig mit auf die Reise der Data Science und der Visualisierung zu nehmen. Darum werden wir heute versuchen, auf den neuen thematischen Merkmalen Auswertungen zu fahren und daraus Visualisierungen zu erstellen. Dabei werden wir auf Schwierigkeiten stoßen, die sich ganz naturgemäß bei solcher Art Daten ergeben.
Nachdem wir dann ein Gefühl für die Sortierungsmerkmale und die Schwierigkeiten bekommen haben, werden wir die Schwierigkeiten im nächsten Artikel umschiffen. Dieser Artikel bildet also mit dem nächsten eine Einheit. Alles zusammen wäre für einen einzigen Artikel etwas viel gewesen. Auch Nichtinformatiker sollen das noch verdauen können.
In diesem und dem nächsten Artikel zusammen werden wir auch lernen, worauf man achten muss, wenn man über eine riesige und extrem komplexe Datenmenge einen Graphen der Themen rendern will – ähnlich zu dem Graphen, der damals das soziale Netz der Spiegel-Autoren dargestellt hat. Nur viel, viel, viel größer.
Rubriken und Unterrubriken
Im ersten Artikel hatten wir schon eine extrem grobe thematische Einordnung der Artikel kennengelernt: Die Rubriken bzw. Ressorts von SpiegelOnline. Hier sind sie noch mal:
Das ist nun wirklich keine sehr feine Einordnung. Wir schauen nun mal oben in den Kopf eines jeden Spiegelartikels. Wie wir direkt sehen können, gibt es noch eine genauere Einteilung. Hier haben wir unser erstes neues Merkmal in diesem Artikel: Die Unterrubrik.
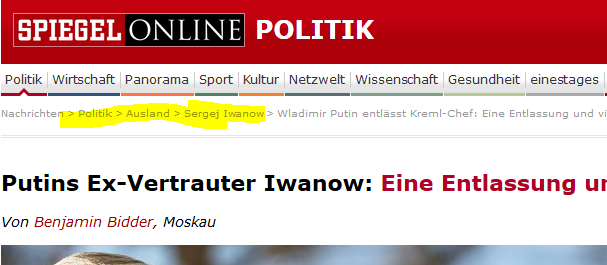
Der Screenshot ist aus diesem Artikel über ein ranghohes Regierungsmitglied, das in Russland zurückgetreten wurde ist. Im Artikelkopf sieht man zur Rubrik „Politik“ die Unterrubrik „Ausland“.
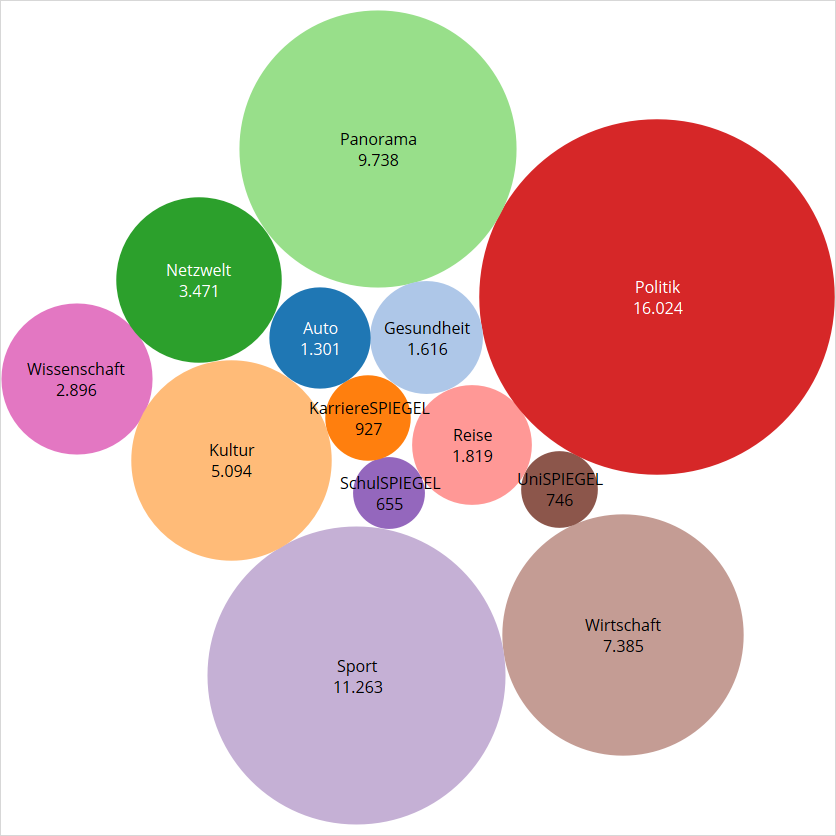
Zu den 13 Rubriken gibt es 51 Unterrubriken. Hier habe ich mal wieder einen Graphen layoutet. Die Größen der Knoten korrespondiert wieder zu den Artikelzahlen der jeweiligen Rubriken und Unterrubriken.
Anhand der Artikelvolumina (= Kreisflächen) kann man wieder auf die Prioritäten schließen. Man sieht auf Anhieb, dass die Sport-Unterrubrik „Fussball“ knapp so groß ist, wie die ganze Wirtschaftsrubrik. Auslands-Politik ist alleine so wichtig wie das ganze Panorama. Deutsche Politik ist so wichtig wie der Kulturteil.
Wir färben das ganze mal wieder nach der altbekannten Textlänge. Keine Sorge – wir werden später noch interessantere Merkmale betrachten, als immer wieder nur die Textlängen! Das wir die so oft rannehmen, liegt daran, dass wir noch nicht so viele andere Merkmale kennen. Außerdem eignet sich die Textlänge immer sehr gut zur initialen Erklärung, weil sie jeder sofort versteht. Und sie ist natürlich auch nützlich, um fieseste Vorurteile zu schüren. 
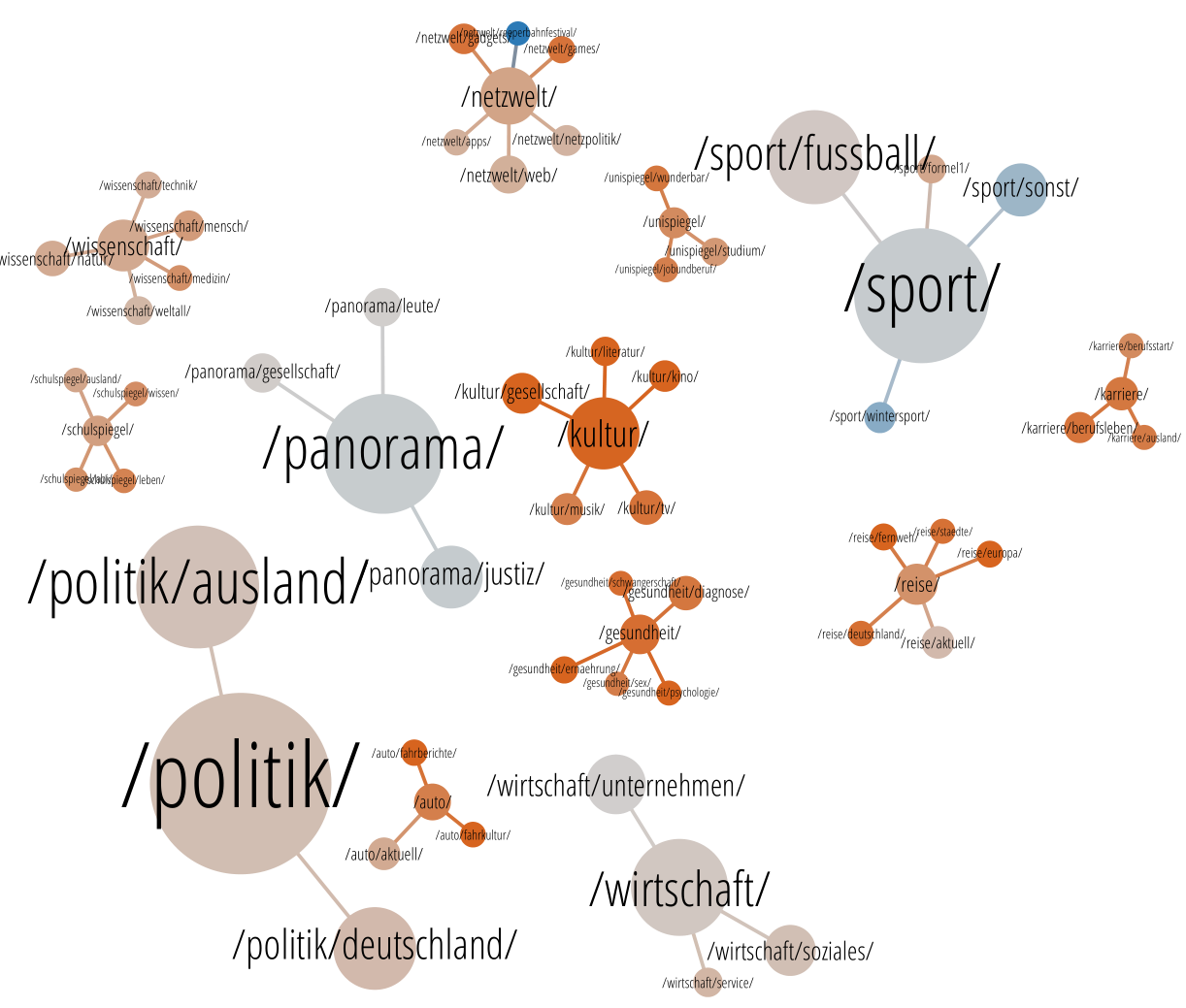
Wie gehabt sind Grautöne nahe der Mediantextlänge. Je blauer, desto kürzer sind die in einer Rubrik / Unterrubrik enthaltenen Artikel. Je Oranger, desto länger. Wir sehen das schon aus den vorherigen Artikeln bekannte grobe Muster, nämlich dass z.B. das Kulturressort die längsten Artikel verfasst, und Panorama und Sport eher kurz sind. Interessant zu betrachten wären Konstellationen, wo eine Subrubrik in der Farbe krass von ihrer Oberrubrik abweicht.
Sowas gibt es hier aber nur ein einziges mal: Während Netzweltartikel insgesamt eher lang sind, gibt es eine Unterrubrik /netzwelt/reeperbahnfestival/, die davon signifikant abweicht – sie ist knallblau. Was ist denn da los? Stellt sich raus, dass das ein großer Anteil Liveberichterstattungen zum Reeperbahnfestival war (beginnen leer, werden downgeloadet, wachsen dann erst) und dann noch ein paar andere Artikel zu demselben Festival, bei denen der Text erst später via Spotify nachgeladen wird (den habe ich nicht erfasst). Warum ausgerechnet das Festival jetzt eine eigene Unterrubrik kriegt, – keine Ahnung. Das ist vielleicht ein redaktionelles Artefakt. Jedenfalls haben die darin enthaltenen 21 Artikel allesamt zwischen 30 und 50 Worten.
Wirklich alle? Nein, nicht ganz alle. Ein einsamer Artikel hört nicht auf, der geringen Wortanzahl Widerstand zu leisten! Und das ist der hier: BKA zerschlägt internationales Botnetz. 243 Worte. Hier ist ein Screenshot:

Warum bitte ist der unter der Unterrubrik „Reeperbahnfestival“ eingeordnet?  Im Text kommt das Festival nicht einmal vor. Aber hey – auch Spiegelredakteure dürfen sich mal verklicken, oder?
Im Text kommt das Festival nicht einmal vor. Aber hey – auch Spiegelredakteure dürfen sich mal verklicken, oder? 
Ich hatte ja versprochen, dass wir in diesem Blogartikel gleich mehrere neue Merkmale kennenlernen. Wir bohren uns jetzt etwas weiter in die Materie und nehmen neben Rubrik und Subrubrik das nächste Merkmal der thematischen Einordnung hinzu.
Eine feinere Einordnung: Die "Themen"
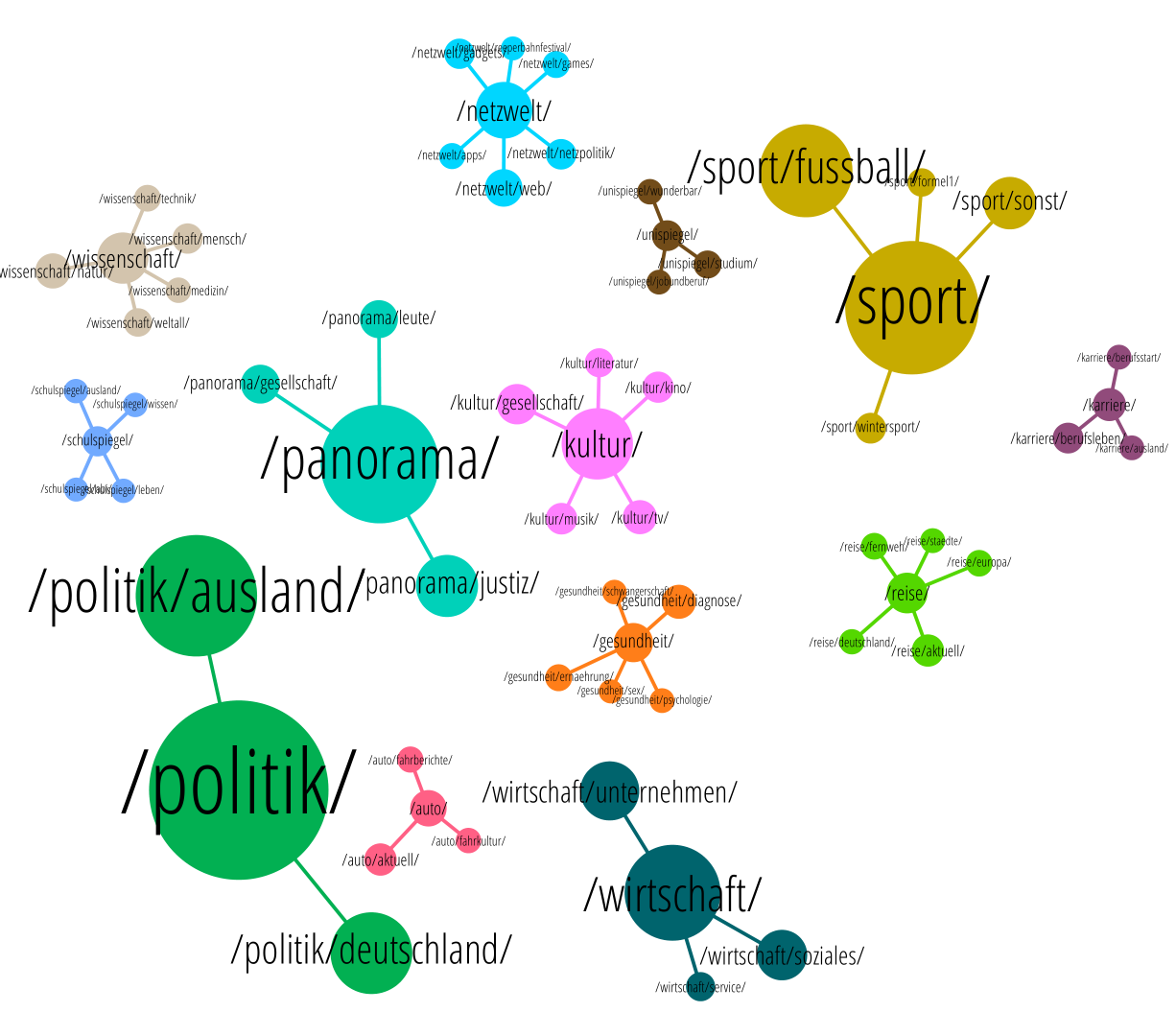
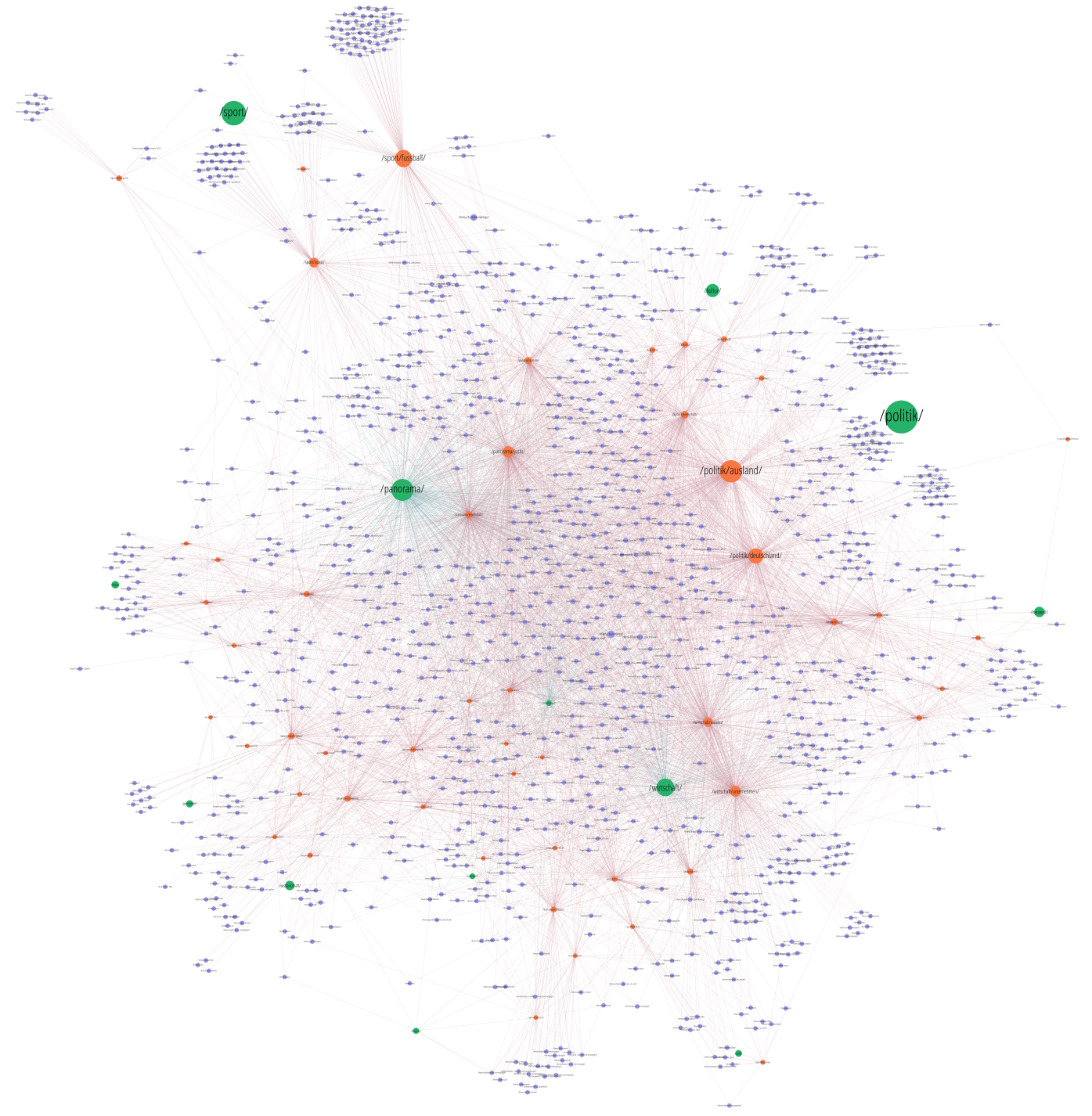
Ihr habt im Bild des eingangs gezeigten Artikels bestimmt schon erspäht, dass da nicht nur „Politik“ und „Ausland“ stehen, sondern auch noch „Sergej Iwanow“ – gewissermaßen als Unterunterrubrik. Das sind aber keine Unterunterrubriken, sondern Spiegel nennt diese Einordnungsstufe „Themen“. Das Artikelthema ist ein weiteres Merkmal, das wir betrachten. Wir erweitern unsere oben gezeigte Landkarte einmal um alle Themen, die mehr als 10 Artikel umfassen. Das macht die Landkarte schon deutlich umfangreicher:
 Hier könnt ihr ein PDF mit dem vollständigen Graph herunterladen. Da kann man dann auch weit reinzoomen, um den Text zu lesen.
Hier könnt ihr ein PDF mit dem vollständigen Graph herunterladen. Da kann man dann auch weit reinzoomen, um den Text zu lesen.
Ich empfehle für das Angucken solch umfangreicher PDFs SumatraPDF. Es ist ein kleiner PDF-Reader ohne großen Schnickschnack, der aber so große PDF-Graphen zackig rendert und in dem vor allem die Volltextsuche bei solchen Graphiken besser funktioniert als beim Acrobat Reader.
Die Oberrubriken sind hier grün eingefärbt, die Unterrubriken orange, und die Themen bläulich. Wie ihr seht, ist das ein ziemliches Kuddelmuddel, weil ein Thema in vielen Unterrubriken (und manchmal sogar direkt in einer Oberrubrik) sein kann. Ein Thema ist nicht etwa einer Unterrubrik fest zugeordnet, sondern kann in mehreren Unterrurbriken vorkommen. Was man sieht, wenn an ein bisschen durch den Graphen geht, ist, dass es Themen gibt, die mächtiger sind als ganze Rubriken oder Unterrubriken. So ist /thema/flüchtlinge/ durchaus größer als diverse Unterrubriken (sucht mal!).
Wenn ihr an diesem Graphen aber insgesamt nicht soviel sehen könnt, ist euch das nicht übel zu nehmen. Ich nehme diesen Graphen extra mal als Beispiel für einen schlecht errechneten Graphen, aus dem man nur mangelhaft Strukturen ersehen kann. So können wir es nämlich später an einem anderen Graphen besser machen. Wir rekapitulieren also jetzt noch mal genau, wie wir den Graph gebaut haben.
Drei ganz wesentliche Eigenschaften eines Graphen sind seine Knoten (= die zu verbindenden Elemente), seine Kanten (= die Verbindungen) und die Kantengewichte (= ein Zahlenwert, der die Wichtigkeit einer Kante angibt) sind.
- Kanten sind Verbindungen zwischen Rubriken, Unterrubriken und Themen. Wir laufen über alle Artikel. Die meisten Artikel haben Rubrik, Unterrubrik und Thema. Diese Artikel erzeugen Verbindungen „Rubrik ↔ Unterrubrik“ und „Unterrubrik ↔ Thema“. Ich habe sozusagen die Themen in der Rangfolge hinter die Unterrubriken gesetzt, weil sie eine feinere Einordnung sind. Andere Artikel haben nur Rubrik und Thema, aber keine Unterrubrik. Diese erzeugen dann eine Verbindung „Rubrik ↔ Thema“.
- Knoten sind eigentlich Artikelgruppen. Wir sagen zwar hier, ein Knoten ist eine Rubrik, Unterrubrik, oder auch ein Thema. Aber es ist wichtig, diese Vorstellung zu erweitern. Ein Rubrik-Knoten „enthält“ alle Artikel in der Rubrik, ein Unterrubrik-Knoten diejenigen in der Unterrubrik, und das gleiche fürs Thema. Dieser Ansatz ist sehr probat, denn über die Gruppen können wir dann verschiedene Messwerte errechnen (z.B. die durchschnittliche Textlänge aller Artikel in einem Knoten oder die Anzahl der Artikel eines Knotens). Anhand dieser Messwerte kann man dann die Knotengröße und -Farbe festlegen und wirklich schön aussagekräftige Bilder schaffen (große Knoten enthalten z.B. mehr Artikel). Im Autorengraph des zweiten Artikels hatten wir das ja genauso gemacht, und es hat sich bewährt. Ja, das bedeutet, dass Artikel in mehreren Gruppen vorkommen können und dort jeweils in die Messwerte einfließen. Hier kommen die meisten Artikel zum Beispiel in drei Knoten vor: In ihrer Rubrik, ihrer Subrubrik und ihrem Thema.
- Alle Kanten werden genommen. Eine Filterung der Kanten findet nicht statt.
- Kantenwichtigkeit: Überall gleich. Der Einfachheit halber sind alle Verbindungen gleich wichtig. Die Wichtigkeit einer Verbindung nennen wir im Fachjargon übrigens auch „Gewicht“.
Wir stellen fest, dass in unserem Rubrik-Unterrubrik-Themen-Graphen gleich mehrere Sachen ungut sind:
- Wir haben die Kanten einfach alle reingenommen, ohne uns Gedanken zu machen, wie wir die unwichtigen auszusortieren.
- Die Kanten, die im Graph sind, sind alle gleich wichtig, weil wir uns nicht die Mühe gemacht haben, sinnvolle Gewichte zu errechnen. Es wäre schön, wenn Verbindungen zwischen Knotenpaaren, die z.B. mehr Artikel gemein haben als andere Knotenpaare, wichtiger wären als andere Verbindungen. Solche „stark verbundenen“ Knotenpaare könnten dann näher beieinander layoutet werden als andere verbundene Knotenpaare, und der Graph gibt direkt einen viel besseren Eindruck davon, welche Knoten verwandter sind als andere. Nachteil: Rechnerisch aufwändiger. Aber den Aufwand muss man treiben. Ich kriege immer Stresspickel, wenn Leute angeblich Graphenanalyse betreiben, aber zu faul sind, ein sinnvolles mathematisches Modell für Verbindungsgewichte zu entwerfen oder auch nur irgendein althergebrachtes zu nutzen. Graphen ohne sinnvolle Gewichte sind wie Picknick ohne Ameisen. Zumindest gilt das in vielen Fällen.
- Meiner Meinung nach sind die Daten selbst nicht so aussagekräftig. Ähnlichkeiten zwischen verschiedenen Unterrubriken und Themen werden von den Daten nämlich gar nicht definiert – zumindest dann, wenn man die Ähnlichkeit an der Menge der gemeinsamen Artikel von z.B. zwei Themen bemessen will, was naheliegend ist. Ein Artikel kann nämlich in maximal einer Rubrik, Unterrubrik und einem Thema sein. Im Resultat sieht man im Graph ja auch ganze strukturlose „Blumensträuße“ an Themen, die einfach an einer Unterrubrik und ansonsten im luftleeren Raum hängen, wie im folgenden Ausschnitt:

Mit anderen Worten: Das ist unbefriedigend so. Entweder müssen wir verbessern, wie wir diesen Graphen generieren. Oder wir brauchen eine bessere Datenquelle, die mehr Informationen trägt, als die Zugehörigkeit der Artikel zu Rubriken, Unterrubriken und Themen. Aus dieser Datenquelle müssen wir dann neue Artikelgruppen errechnen, die unsere Knoten repräsentieren. Dann müssen wir sinnvoll wählen, welche möglichen Kanten wir in den Graph mit aufnehmen. Eine Filterung ist hier sinnvoll, um den Graphen nicht zu überladen, denn dann hat man nur ein einzelnes Knäuel. Und für die Kanten, die wir aufnehmen, müssen wir ein sinnvolles mathematisches Maß finden, wie wichtig die jeweils sind (= wie ähnlich Artikelgruppen zueinander sind).
Anmerkung für die graphentechnisch Interessierteren unter euch: Das Problem, dass direkte Verwandtschaftsbeziehungen zwischen Themen von den Daten hier nicht gut definiert werden, könnte man auch folgendermaßen lösen:
- Man entfernt die Unterrubriken- und Rubrikenknoten und lässt sie in neuen Kanten aufgehen.
- Die neuen Kanten sind dann Kanten zwischen jeweils zwei Themen. Die Wichtigkeit einer Kante ist dann dadurch definiert, in wievielen Subrubriken/Rubriken die beiden Themen gemeinsam vorkommen. Themen die oft in denselben Rubriken vorkommen, sind dann „verwandter“.
Dann hat man einen Graph, der nur aus Themen und Verbindungen zwischen diesen besteht. Diesen Aufwand könnten wir natürlich jetzt betreiben. Mein Bauchgefühl sagt mir aber, dass dieser Ansatz zwar eine visuelle Verbesserung bringt, aber in sich dennoch grob ist. Da wir ausserdem bald was besseres finden, verfolge ich das hier nicht weiter.
Zurück zum Thema. Wir wollten eine neue Datenquelle erschließen. Dabei müssen wir darauf achten, dass diese so reichhaltig ist, dass man z.B. Verbindungsgewichte auch sinnvoll errechnen kann. Knotenpaare, die durch wichtige Kanten verbunden sind, werden dann näher beieinander layoutet, als solche, deren Verbindung eher unwichtig ist.
Und damit kommen wir zum wichtigsten Merkmal, dass wir in diesem Artikel kennenlernen.
Die Keywords
SpiegelOnline bietet noch eine viel, viel freiere und informationstragendere thematische Einordnung der Artikel: Die Keywords oder auch Schlagwörter. Jeder Artikel bekommt eine Liste solcher Keywords zugewiesen. Die Keywords stehen im Artikelsourcecode drin, die können wir also als Merkmal auslesen. Beispielsweise sind die Keywords unseres oben genannten Beispielartikels: Politik, Ausland, Sergej Iwanow, Kreml, Russland, Wladimir Putin.
Wir stellen fest: Rubrik, Unterrubrik und Thema sind auch Keywords. Das könnt ihr sofort sehen. Zweitens; Bezogen auf die durchschnittliche Zahl der Keywords pro Artikel sind das eher wenige. Der Durchschnitt liegt bei knapp neun (dazu gleich noch mehr). So sieht die Verteilung der Keyword-Anzahlen aus:
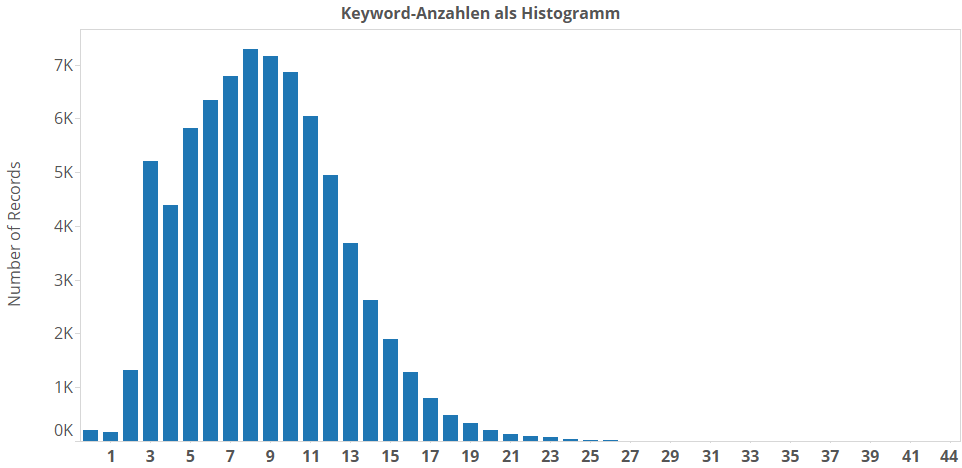
Wie wir sehen, haben die allermeisten Artikel zwischen drei und zwanzig dieser Keywords. Wenn ein Artikel mehr Themen abdeckt, dann hat er eben einfach mehr Keywords. Die Vielfalt der Keywordkombinationen, die an einen Artikel vergeben werden kann, ermöglicht eine viel, viel genauere thematische Einordnung als die bis jetzt bekannten Merkmale Rubrik, Unterrubrik und Thema. Dieser Datenwust ist natürlich auch schwerer auszuwerten. Wir schlüsseln das ganze mal auf nach Rubriken:

Und jetzt ziehen wir die Balken nach oben breit. So verlieren wir wieder das Gefühl für die Menge der Artikel mit der jeweiligen Anzahl an Keywords, aber wir können viel besser sehen, welche Rubrik wo dominiert:
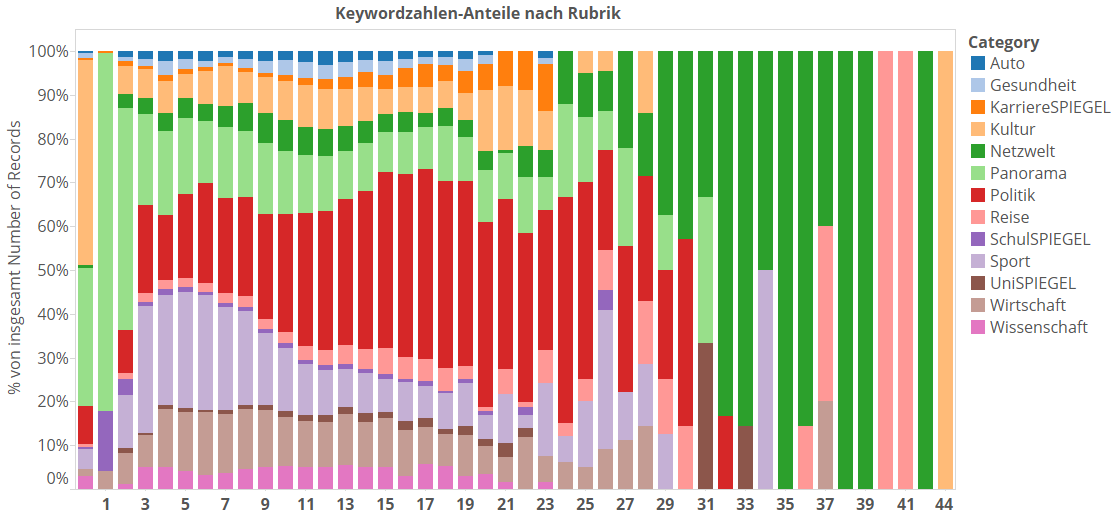
Ich wiederhole: Ab der Keywordsanzahl von 20 gibt es kaum mehr Artikel, deswegen tritt ab da eine starke, ausreißerbasierte Verzerrung ein. Was auf den ersten Blick auffällt ist, dass diese extrem hohen Werte fast alle von der dunkelgrünen Netzwelt dominiert werden.
Ich habe mal reingeguckt: Die Netzweltartikel ab Keywordzahl 29 kommen fast alle von Sebastian Meineck, der hiermit den Sonderpreis „Keywordgenerator“ erhält.  Bei den Artikeln handelt es sich um Auflistungen, was es gerade alles im Netz geschenkt gibt. Hier ist ein Beispielartikel. Diese Artikel gehen über ganz viele verschiedene Sachen, die dann alle auch als Keyword verewigt werden. Spitzenreiter mit strammen 44 Keywords ist dieser Artikel – wieder eine Auflistung, dieses mal von Büchern.
Bei den Artikeln handelt es sich um Auflistungen, was es gerade alles im Netz geschenkt gibt. Hier ist ein Beispielartikel. Diese Artikel gehen über ganz viele verschiedene Sachen, die dann alle auch als Keyword verewigt werden. Spitzenreiter mit strammen 44 Keywords ist dieser Artikel – wieder eine Auflistung, dieses mal von Büchern.
Eine kleine Überraschung ergibt sich, wenn man betrachtet, wie viele Keywords denn so über die Zeit pro Artikel verwendet wurden. Da gibt es nämlich einen richtig harten Schnitt:
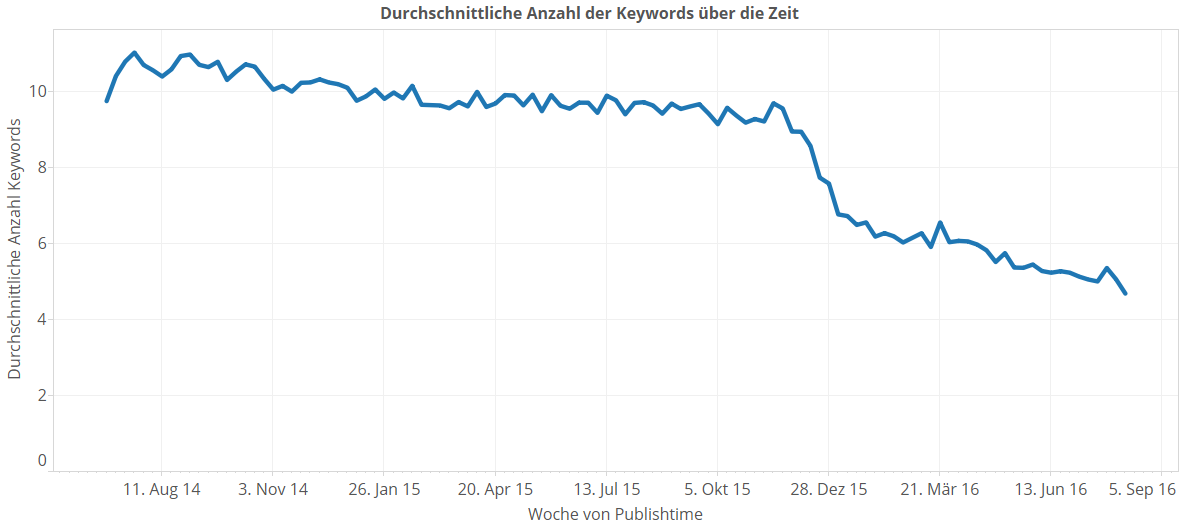
Während vor dem Jahreswechsel 2015/2016 im Schnitt 10 Keywords pro Artikel üblich waren, geht die Anzahl seit Anfang 2016 im Schnitt gegen 5. Auch abseits des Sprungs ist die Tendenz leicht sinkend. Hier scheint es eine redaktionelle Anweisung gegeben zu haben, sich etwas im Zaum zu halten. Ob Herr Meineck im Fokus dieser Ansage stand, konnte ich leider nicht in Erfahrung bringen.
Nachdem wir jetzt wissen, wie viele Keywords Artikel so enthalten, wie ist es denn umgekehrt? Wie oft werden denn die Keywords wiederverwendet? Die einfache Antwort lautet: Im Schnitt 9.73 mal. Und im Median 1 mal. Diese krasse Abweichung bedeutet, dass man mit diesen einfachen Werten sehr aufpassen muss und die Verteilung irgendeine Form von Schlagseite hat.
Die schwerere, aber genauere Antwort ist also, dass einem Median und Durchschnitt hier nicht soviel bringen und man genauer hinschauen muss. Das machen wir jetzt mal kurz: Aktuell kommen in der Sammlung 66278 Keywords vor. Von denen kommen überhaupt nur 6696 Keywords in mindestens 10 Artikeln oder mehr vor. Das heisst: 90% aller Keywords kommen weniger vor als zehn mal. Nach dem obigen Median kommt sogar die Hälfte der Keywords nur einmal vor. Keywords, die extrem selten vorkommen, können z.B. einfach Tippfehler sein oder nur winzige Themen. In jedem Fall sind sie für Statistiken weniger interessant, da die Artikelgruppen, die sie repräsentieren, sehr klein sind. Auf der anderen Seite gibt es einige wenige extrem riesige Keywords, wie diejenigen, die ganze Rubriken repräsentieren (Beispiel: Politik mit mehr als 18.000 Vorkommen). Das sind die, die den Durchschnitt nach oben getrieben haben.
Kurz zusammengefasst: Es gibt extrem viele, sehr kleine Keywords. Und extrem wenige, dafür aber sehr große Keywords. Das ist wie mit Erdbeben. Jeden Tag gibt es winzige, nicht spürbare Erschütterungen der Erde. Alle paar Jahre rumpelt es mal spürbar. Und sehr selten knallt es mal so, dass eine ganze Stadt abgeräumt wird. Bei solchen Verteilungen muss man irgendwo den Schwellwert ziehen, ab dem man die Ereignisse beachten will. Später werden wir diesen Schwellwert bei 10 ziehen. Alle Keywords, die kleiner sind, werden wir dann wegfallen lassen.
Zum Abschluss schauen wir uns noch an, wie die zeitliche Verteilung einiger ausgewählter Keywords über die Zeit zu ein paar ausgewählten Themen ist. Ich habe absichtlich ein paar reißerische Themen rausgesucht, damit sich jeder sofort erinnert – und absichtlich ein paar, über die sehr kurz oder aber über einen längeren Zeitraum berichtet wurde. So können wir schauen, ob wir mittels der Keywords auch tatsächlich thematische Ausschläge sichtbar machen können – sprich, wann über das jeweilige Thema berichtet wird. Wir werden daran ein Problem sehen, dass sich ganz natürlich bei so semi-strukturierten Datenmengen wie „Keywordlisten pro Artikel“ ergibt.
Wir fangen mal an mit der Partei, die im Moment sämtliche Beliebtheitspreise abräumt – der AfD. Ich bitte das nicht als Wahlwerbung misszuverstehen, dass ich genau die nehme, hat einen Grund. Links sind die Keywords aufgeschrieben, und die Diagrammbalken geben die Häufigkeiten pro Woche an.

Überraschenderweise betrachte ich hier direkt zwei Keywords auf einmal: „afd“ und „alternative für deutschland (afd)“. (Ja, Keywords können auch aus mehreren Worten bestehen.)
Das Keyword „alternative für deutschland (afd)“ scheint das „Hauptkeyword“ zu sein, denn darunter gibt es viel mehr Artikel (die Y-Achsen der beiden Keywords sind unabhängig voneinander, beachtet, dass die untere viel höher geht!). An diesem Keyword kann man sehen, dass die Berichterstattung über die AfD seit Anfang 2016 stark zugenommen hat. Das ist auch ganz natürlich, da waren ja Landtagswahlen, wo die AfD überraschend gut abgeschnitten hat (beachtet den Peak im März).
Wir haben gelernt: Ja, wir können sehr gut an den Keywords messen, wann welches Thema in den Medien sehr präsent war. Sehr schön! Wir haben jetzt auch gelernt, dass es mehrere Keywords zu demselben Thema geben kann. Mutmaßlich gibt es sogar noch ein paar mehr Keywords zum Thema. Sowohl „afd“ als auch „alternative für deutschland (afd)“ werden durchgehend mit Artikeln bestückt. Die laufen beide fast gleichwertig nebeneinander her, auch wenn eins häufiger bestückt wird. Hier hat man sich also nicht so recht entscheiden können. Ich vermute, dass die Autoren die frei eingeben können und allenfalls eine Suchhilfe für bereits existierende Keywords erhalten.
Nächstes Thema: Germanwings und der berüchtigte Massenmord-Flugzeugabsturz in den französischen Alpen. Ich habe uns wieder gleich mehrere Keywords rausgesucht (es wird auch hier noch mehr geben).

Wir sehen, wie über die ganze Zeitspanne hin und wieder mal allgemein über das Keyword „germanwings“ berichtet wird, und dass das Keyword auch das mächtigste der fünf gezeigten ist. Im Frühjahr 2015 erfolgte der Absturz, da gibt es einen klaren Peak. „andreas lubitz“ ist der Pilot des Unglückfluges. Für uns ist klar, dass das Keyword „andreas lubitz“ zum keyword „germanwings“ verwandt sein muss. Da Herr Lubitz sonst nicht groß vertreten ist, wird sein Keyword sogar eine Art Untermengenbeziehung zum Keyword „germanwings“ haben: Wahrscheinlich enthalten Artikel mit „andreas lubitz“ meistens auch „germanwings“, aber nicht umgekehrt. Wie ihr seht, kann sozusagen ein Keyword für das andere wichtig sein, aber umgekehrt muss das nicht unbedingt auch der Fall sein. Unerwiderte Liebe, nur mit Keywords.
Es gibt aber noch was im Bild zu lernen. Die Flugnummer des Unglücksfluges war 4u9525. Die ist als Keyword in zwei Schreibweisen vorhanden: Mit und ohne Leerzeichen. Das kann man im Grunde nicht als Tippfehler zählen, beides ist ja völlig valide, auch wenn sich die Variante ohne Leerzeichen klar durchgesetzt hat (die Variante mit Leerzeichen kommt nur zweimal vor). Auch solche Unschärfen können also auftreten und sind in den Daten zu erwarten. Und zum Schluss sieht man noch einen Tippfehler: Die Flugnummer 4u9565. Die wurde, wenn ich mich recht erinnere, zu Anfang von den Medien kolportiert, das stellte sich aber als Fehler heraus (dass man sowas sehr leicht auf den Seiten der Airlines hätte verifizieren können, ist eine andere Geschichte). Wir sind in den Keywords also auch nicht vor Tippfehlern gefeit. Wie gesagt, die Autoren scheinen die frei Wählen zu können. Auch die falsche Flugnummer kommt nur zweimal vor.
Nächstes Thema: Die Flüchtlingskrise (huhu, Kristin! ).
Hier habe ich die beiden Keywords „flüchtlinge“ und „flüchtlinge in deutschland“ ausgegraben. Auch hier wird es wieder etliche weitere geben.
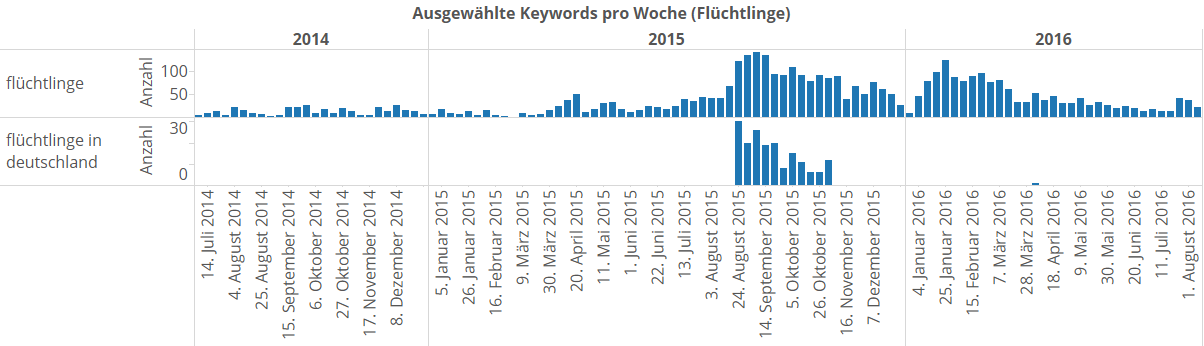
Zum einen sieht man, dass „flüchtlinge“ klar dominiert und dass die Berichterstattung im Spätsommer 2015 sprunghaft angeschwollen ist. Aber man sieht auch: „flüchtlinge in Deutschland“ war, obwohl es dominiert hat, durchaus ein großes Keyword, und ist dann sprunghaft nicht mehr benutzt worden. Das könnte eine interne Teamorder sein, dass man sich jetzt bitte auf das Keyword „flüchtlinge“ zu einigen hat.
Was wir jetzt gesehen haben, sind die Kernprobleme der Datenquelle der Keywords: Es kann gut und gerne mehrere Keyword-Varianten zu demselben Thema geben, die irgendwie beide dauerhaft nebeneinanderher geführt werden. Manche Keywords sind untereinander verwandt, andere nicht, und es gibt sehr einseitige Verwandschaften. Es ist davon auszugehen, dass es zu Berichterstattungsthematiken einfach ganze Keywordgruppen gibt – mit anderen Worten, dass die Artikel zur jeweiligen Thematik einfach alle oder fast alle Keywords der Gruppe enthalten. Dennoch garantiert uns das aber keiner. Kurz: Der Datensatz ist unscharf, redundant und verrauscht, aber er enthält trotzdem sehr, sehr viel Information. Zusätzlich ist er extrem hochdimensional. Liebe Leser, willkommen in der DataScience. Genauso sieht die Realität aus.
Unser Ziel im nächsten Artikel wird sein, mit diesen Phänomenen klar zu kommen, sie zu überwinden, verwandte und einseitig verwandte Keywords zu finden, Redundanzen zu eliminieren und eine konsistente Visualisierung zu schaffen, die diesen Unschärfen so gut es geht ausweicht.
Kurz: Wir bringen Ordnung ins Chaos.
Ich freu mich drauf!