
Inhaltsverzeichnis
![]()
SpiegelMining: Wer, wann, was, mit wem? Das soziale Netz der SpiegelOnline-Redakteure
Ihr habt bestimmt schon mal beobachtet, dass es im Internet immer genau dann besonders knusprig wird, wenn personenbezogene Daten ins Spiel kommen  . Diesem Umstand eingedenk fügen wir unserem SpiegelMining heute die Autoren eines jeden Artikels hinzu. Und dazu führen wir auch gleich noch eine weitere, sehr schöne Art der graphischen Darstellung ein. Ob sich daraus auch überraschende Erkenntnisse ergeben – ihr dürft gespannt sein.
. Diesem Umstand eingedenk fügen wir unserem SpiegelMining heute die Autoren eines jeden Artikels hinzu. Und dazu führen wir auch gleich noch eine weitere, sehr schöne Art der graphischen Darstellung ein. Ob sich daraus auch überraschende Erkenntnisse ergeben – ihr dürft gespannt sein.
Was bisher geschah: Im letzten Artikel zum Thema haben wir gelernt, wie ich über die letzten 2 Jahre über 70.000 Artikel von SpiegelOnline heruntergeladen habe und nun auswerte. Wir haben besprochen, dass wir aus den Artikeln Merkmale zum Auswerten herausziehen. Letztes mal waren das erstmal einfache Merkmale: Der Erscheinungszeitpunkt eines Artikels, dessen Rubrik und seine Textlänge. Bereits durch das Nebeneinanderhalten und Aufplotten dieser einfachen Merkmale sind wir auf Systematiken gestoßen, die für den einen oder anderen überraschend waren – nämlich, dass SpiegelOnline nach einem offensichtlich festen System lange und kurze Artikel nach Tageszeiten ordnet.
Dies ist erst der zweite Artikel, also bauen wir immer noch langsam unser grundlegendes Auswertungsgebäude auf, von dem wir später bei weiteren Auswertungen zehren werden. Obwohl wir alles noch aufbauen, wird es wie im letzten Artikel auch hier wieder ein paar Resultate geben, sonst macht es ja auch keinen Spaß.
Ich versuche ja immer, euch zumindest auf oberflächliche Weise auch ein bisschen am Technikteil teilhaben zu lassen. Also gibt es vor den eigentlichen Ergebnissen zunächst noch ein paar Anekdötchen des Auswertevorgangs selbst, damit ihr wisst, wie sowas grundlegend ablaufen kann.
Es war extrem nervig, die Autoren auszulesen
Direkt zu Anfang, wenn man die Autoren aus den Spiegelartikeln ziehen will, fällt einem auf, dass diese in den Spiegelartikeln nicht nur nicht immer am selben Ort stehen (wir kommen darauf im nächsten Artikel noch mal zurück, ich verspreche eine kleine Überraschung). Oftmals werden die Namen auch gar nicht ausgeschrieben sondern durch Kürzel reproduziert. Ich gebe zwei Beispiele:
In diesem Artikel über den Würzburger Axtmörder findet sich direkt unterhalb des eigentlichen Inhalts eine kursive Autorenangabe in Kürzeln: sms/dpa/AFP/Reuters. Wie wir sehen, sind dort auch die Nachrichtenagenturen enthalten.

Dann gibt es andere Artikel wie diesen hier über Donald Drumpf1), wo keine Autorenangabe unten nach dem Text kommt, dafür aber ausgeschriebene Namen der Autoren direkt unter dem Titel stehen:
Technisch gesehen laufe ich nun durch sämtliche Artikel und sammle erstmal alle Namen und Abkürzungen von den beiden möglichen Stellen (oben und unten) ein, die ich finde. Nun ist das Problem, dass die Zeilen, die Namen und Abkürzungen enthalten, beim Spiegel nicht standardisiert sind. Das wäre ja auch zu einfach. Nein, sie sind auf ganz unterschiedliche Arten und Weisen formuliert. Die meisten Namen und Abkürzungen kriege ich aber erfolgreich mit (ich weiß jetzt mehr über Regular Expressions als ich jemals wissen wollte). An sowas kann man schon mal ein paar Tage rumknobeln, bis es richtig gut funktioniert. Für alle die denken, da muss man nur ein paar Vornamen und Nachnamen suchen: Unterscheidet die doch mal von den restlichen Wörtern, insbesondere wenn es Kollegen wie den Herrn Philipp Alvares de Souza Soares gibt, dessen Name aus 5 Wörtern besteht. Na, hat ja geklappt.
In einem zweiten Schritt laufe ich dann nochmals über alle Artikel. Bei jedem Artikel checke ich, ob ich vielleicht noch einen Name oder eine Abkürzung vergessen habe von denen, die mir aus dem ersten Durchlauf bekannt sind. Dieser Durchlauf vergenauigt das Ergebnis noch einmal sehr.
Bleibt das Problem der Abkürzungen – man will ja gerne Klarnamen und keine Abkürzungen. Den Schlüssel hierfür liefert der Spiegel selbst, und zwar hier. Auf dieser Seite finden sich alle möglichen Redakteursnamen samt zugehöriger Abkürzungen. Die Seite wird auch regelmäßig vom Spiegel aktualisiert. Ich werte sie automatisiert aus und speichere mir die Zuordnungen von Abkürzungen zu Namen. So schaffe ich es, vollautomatisch sehr viele Abkürzungen in Namen zu übersetzen. Der Rest der Abkürzungen bleibt wie er ist.
Im Ergebnis finde ich (Stand: Datensatz vom 17. Juli 2016) zu knapp 90% aller Artikel wenigstens einen Autor. Diese Quote ist gar nicht so schlecht, weil bei einer guten Menge an Artikeln gar keine Autoreninformationen dransteht. Ich schaffe weiter, 84% der angetroffenen Abkürzungen in Klarnamen zu übersetzen (dieser Wert ist gefühlt niedriger, weil ich hier auch die Nachrichtenagenturen mitzähle, und die kommen häufig vor).
Insgesamt sind das auf jeden Fall genug Daten, um ordentliche Auswertungen darüber betreiben zu können. Ich erzähle das aber auch darum so genau, damit wir zu uns selbst ehrlich sind und im Hinterkopf behalten, dass kleinere Unschärfen vorkommen können.
Einfache Betrachtungen: Artikel pro Autor und Autoren pro Artikel
Wir fangen mal einfach an. Ich habe 1743 Autoren insgesamt in meiner Sammlung. Die allermeisten Artikel (ca. 85,7%) haben genau einen einzigen Autor (hier sind die Agenturen rausgerechnet). Zwei Autoren kommen auch noch häufiger vor (ca. 5,6%). Ab drei Autoren (ca. 0,77%) werden die Artikel immer weniger. Die Top 3 meiner Sammlung von mehr als 70.000 Artikeln sind:
- Hier einer über Snowden mit sagenhaften neun Autoren, das ist in meiner Sammlung der Spitzenreiter.
- Hier einer zum Gotthard-Tunnel mit acht Autoren
- Hier noch mal einer mit acht, sehr schön zu sehen hier die Kürzel. Der Artikel ist eigentlich eine Bilderserie.
Autoren pro Artikel sind das eine. Machen wir mal das umgekehrte: Artikel pro Autor. Wer schreibt denn die meisten Artikel? Die Verteilung sieht zunächst ähnlich aus: Es gibt sehr viele Autoren die an nur wenigen Artikeln beteiligt sind – und einige wenige Autoren, die an sehr vielen Artikeln beteiligt sind. Die Top Ten sind:
- Christoph Sydow ist mit Beteiligung an 1667 Artikeln der Spitzenreiter – das sind ca. 2,4% der gesamten bis jetzt gesammelten Spiegelartikel! Respekt! Er arbeitet im Ressort Politik, das ist ja auch eines der dominierenden im Spiegel, wie wir aus dem letzten Artikel wissen.
- Peter Ahrens (1504 Artikel),
ebenfalls im Ressort Politikim Ressort Sport (verbessert, sorry, da hatte ich mich vertippt). - Jens Witte (1476 Artikel), Panorama, auch eines der dominierenden Ressorts
- Peter Maxwill (1347 Artikel), ebenfalls Panorama
- Anna-Lena Roth (1209 Artikel), auch Panorama
- Benjamin Schulz (1082 Artikel), na was wohl…? Panorama.
- Vera Kämper (1067 Artikel), Politik
- Gesa Mayr (892 Artikel), die ist bei der Kinderabteilung „Bento“ zuständig

- Britta Kollenbroich (869 Artikel), Wirtschaft (endlich mal wieder was neues!)
- Christian Teevs (809 Artikel), noch mal Politik.
Man sieht schon, wie rasch die Artikelzahlen weniger werden, wenn man sich vom ersten Platz nach unten wegbewegt. Das kann man auch in Zahlen fassen: 75% der Autoren waren an maximal 12 Artikeln beteiligt (mathematisch ausgedrückt: Das 75. Perzentil ist 12). Die Hälfte der Autoren hat sogar nur drei Artikel oder weniger. Falls euch das wundert: Das kommt durch die vielen Gastschreiberlinge zustande, die irgendwann mal gebeten werden, was beizutragen, und fortan nicht mehr gesehen werden. Nur zehn Prozent der erfassten Autoren haben 80 Artikel oder mehr.
Viele weitere einfache Betrachtungen sind denkbar, gerade im Zusammenhang mit dem Veröffentlichungszeitpunkt der Artikel oder der Rubrik.
- Man kann die Veröffentlichungskönige nach Zeit zählen
- Man könnte pro Monat zählen, wieviel verschiedene Autoren zu Rubriken beitragen und so sehen, welche Rubriken personell zusammengestrichen werden. Schreibt mir einfach, wenn ihr solche Sachen mal wollt, ich versuche die dann einzubauen.
- Falls die Zahl der verschiedenen Autoren jeden Monat irgendwann stark abnimmt, deutet das auf eine Kündigungswelle hin (habe ich mal geguckt, gab es nicht, es gibt zur Mitte 2015 hin einen ca. 10% Abschwung in der Autorenzahl, aber nichts ultrakrasses)
- Man kann Einstellungs- und Austrittszeitpunkte sehen (jemand fängt plötzlich an zu veröffentlichen oder hört auf).
Jetzt aber weg von den ganz einfachen Betrachtungen – man kann aus solchen Datensätzen mehr rauslesen, als man auf Anhieb sieht. Und das machen wir jetzt, und dazu generieren wir auch eine neue Art Graphik und erklären sie.
Man kann ganze Teamstrukturen aus vermeintlich oberflächlichen Daten lesen ...
Wir treten noch mal einen Schritt zurück und machen uns klar, was wir für einen Datensatz wir jetzt gerade betrachten. Wir haben mehr als 70.000 Artikel, aber eigentlich betrachten wir die Artikel gerade gar nicht. Was wir gerade betrachten, ist für jeden dieser Artikel eine Liste von Autoren, die den Artikel geschrieben haben.
Im Fachjargon sagt man, man betrachtet nur die „Metadaten“ – sozusagen das, was auf dem Umschlag steht, aber nicht das was drin ist. Wir betrachten die Schreiberlinge, aber nicht den Artikelinhalt selbst. Das ist wie wenn nur SMS-Sender und -Empfänger betrachtet werden, aber nicht der SMS-Inhalt selbst. Oder an einer eMail beteiligte Personen, ohne den Mailinhalt. Wenn euch also einer erzählt, dass man aus solchen spärlichen Metadaten sowieso nichts rauslesen kann, dann könnt ihr euch ja in diesem Artikel selbst eine Meinung bilden.
Durch die Autorenlisten zu jedem Artikel wissen wir nämlich viel mehr als nur, wer einen Artikel geschrieben hat. Wir wissen, wer mit wem Artikel geschrieben hat, und sogar wie oft diese Autorenpaare Artikel zusammen geschrieben haben. Das heißt, wir wissen nicht nur, wer mit wem zusammenarbeitet, sondern wir können auch messen, wie stark die Beziehungen zwischen den Autoren sind.
Die Punkte in der nachfolgenden Grafik sind Autoren. Dicke Punkte sind Autoren mit vielen geschriebenen Artikeln, kleinere Autorenpunkte sind Autoren mit weniger Artikeln. Diverse Autoren sind untereinander verbunden (man sieht viele Verbindungen im Bild, das Bild ist sehr groß, die sind also sehr fein).
Autoren, die verbunden sind, haben mindestens einen Artikel zusammen geschrieben. Autoren, die verhältnismäßig häufig zusammen schreiben, arbeiten offensichtlich enger zusammen. Solche Autoren werden dann näher beieinander layoutet, als welche, die nur selten oder gar nicht zusammen schreiben. Wir erhalten so eine „Beziehungslandkarte“ zwischen den Autoren, alleine aus den Artikelmetadaten. Sucht doch zur Übung mal die Artikelspitzenreiter, die wir oben aufgelistet haben!
 Hier könnt ihr ein PDF mit dem vollständigen Graph herunterladen.
Hier könnt ihr ein PDF mit dem vollständigen Graph herunterladen.
Anmerkung: Bei den Graphenbildern bringe ich immer einen Ausschnitt des Graphs direkt im Artikel. Wer will kann drauf klicken und kriegt den Ausschnitt dann sofort als Bild vergrößert. Pro Graph gibt es aber auch noch direkt unter dem jeweiligen Bild ein PDF zum Download, da ist dann der ganze Graph drauf und vor allem kann ein PDF Volltext-durchsucht werden. So könnt ihr nach bestimmten Autoren suchen, wenn ihr wollt.
Wenn ihr das PDF aufmacht, seht ihr auch ein paar Klein-Cliquen von Autoren, die nicht an den „Hauptkontinent“ angebunden sind, die sind an den Rand gerutscht. Weiter sind im Bild nur Autoren enthalten, die überhaupt mit anderen verbunden sind (es gibt komplett-Einzelgänger gerade unter den Gastautoren, die habe ich für diese Ansicht gefiltert).
Wir testen das Layout des Graphs: Ressorts visualisieren
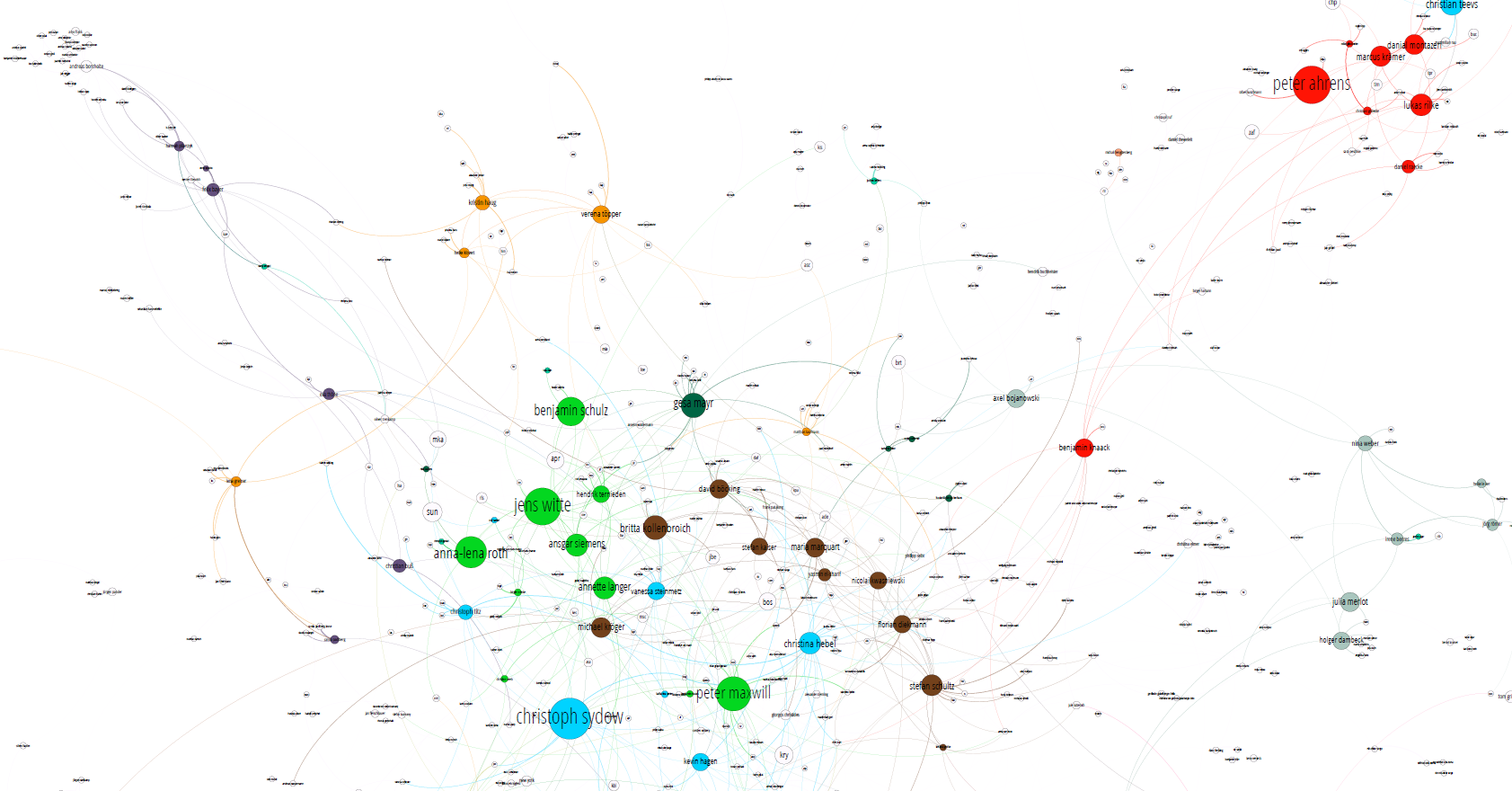
Man sieht im Graph Gruppenbildung. Diese Gruppen scheinen der internen Teamstruktur bei SpiegelOnline zu entsprechen. Die Teamstruktur scheint also einfach so aus den Metadaten entstanden zu sein! Aber das müssen wir nicht nur mutmaßen und auf die Richtigkeit der Visualisierung hoffen, sondern wir können das auch verifizieren: Im Impressum von SpiegelOnline sind nämlich die Ressortzugehörigkeiten von einigen Personen angegeben. Wir färben die Autoren mal nach den Zugehörigkeiten ein und dann gucken wir mal, was rauskommt. In der folgenden Graphik findet sich derselbe Ausschnitt wie oben, nur eben eingefärbt:
 Hier könnt ihr ein PDF mit dem vollständigen Graph herunterladen.
Hier könnt ihr ein PDF mit dem vollständigen Graph herunterladen.
Man sieht an den Farben, wie sich Autoren derselben Ressorts in der Tat tendenziell nahe zusammen finden. Auf Anhieb sichtbar ist das in den Ressorts Panorama (Grün), Wirtschaft (Braun) und Sport (Rot), aber auch bei den meisten anderen. Interessant ist das Ressort Politik (Türkisblau) als Ausreißer: Hier scheint sehr interdisziplinär gearbeitet zu werden, es scheint fast so, als hätten die verschiedenen anderen Ressorts jeweils einen „Stammpolitiker“, mit dem sie dann Artikel schreiben (bei den Sportlern wäre das z.B. Christian Teevs, oben rechts im Ausschnitt, leicht abgeschnitten). Insofern verteilen sich die Politik-Autoren über die ganze Landkarte.
Beachtet außerdem die ganzen weißen Autoren. Das sind Leute, für die ich im Impressum keine Zuordnung gefunden habe. Das Interessante an einer solchen Landkartendarstellung ist nämlich, dass man plötzlich über die unzugeordneten Autoren etwas aussagen kann, je nach dem, wo sie in die Landkarte eingeordnet werden. Gerade diejenigen, die viele Artikel geschrieben haben aber nur noch als Kürzel vorhanden sind, sind vermutlich ehemalige Angestellte des Ressorts, in das sie hineinlayoutet wurden, nur sind sie eben jetzt nicht mehr im Impressum des Spiegel vorhanden.
Zur Unterstützung dieser These sucht beispielsweise mal nach Anna Reimann im Graphen. Hier ein Ausschnitt:

Anna Reimann ist (direkt erkennbar anhand der Verbindungsfarben) zum Autoren im Ressort „Politik verbunden, in meinem Graph aber weiß, also unzugeordnet. Schaut man auf Anna Reimanns Seite bei SpiegelOnline, steht da aber, dass sie sehr wohl im Ressort Politik arbeitet. Sie war aber im Impressum, das ich für die Einfärbung genommen habe, unter „Berlin“ einsortiert – das ich nicht als Ressort genommen habe. Darum war sie bei mir uneingefärbt. Ihr seht also, dass unsere graphbasierte Auswertung relativ mächtig ist, beispielsweise, wenn man Personen einfach durch Beziehungen zu anderen Personen richtig einordnen will. Alles nur auf Metadaten!
Graphbasierte Auswertungen wie die hier gezeigte sind aber auch extrem mächtig, um landkartenartig (und damit deutlich mehr Informationsvermittelnd als normale Diagramme) verschiedenste andere Sachen zu visualisieren. Im letzten Artikel haben wir Balkendiagramme genutzt und Datensätze z.B. in Stunden unterteilt, und über die Teildatensätze irgendwas berechnet. Da ist so ein Graphlayout, wo über die Knoten was berechnet wird, die dazu noch sinnvoll layoutet und nicht nur nebeneinandergestellt werden, schon deutlich cooler.
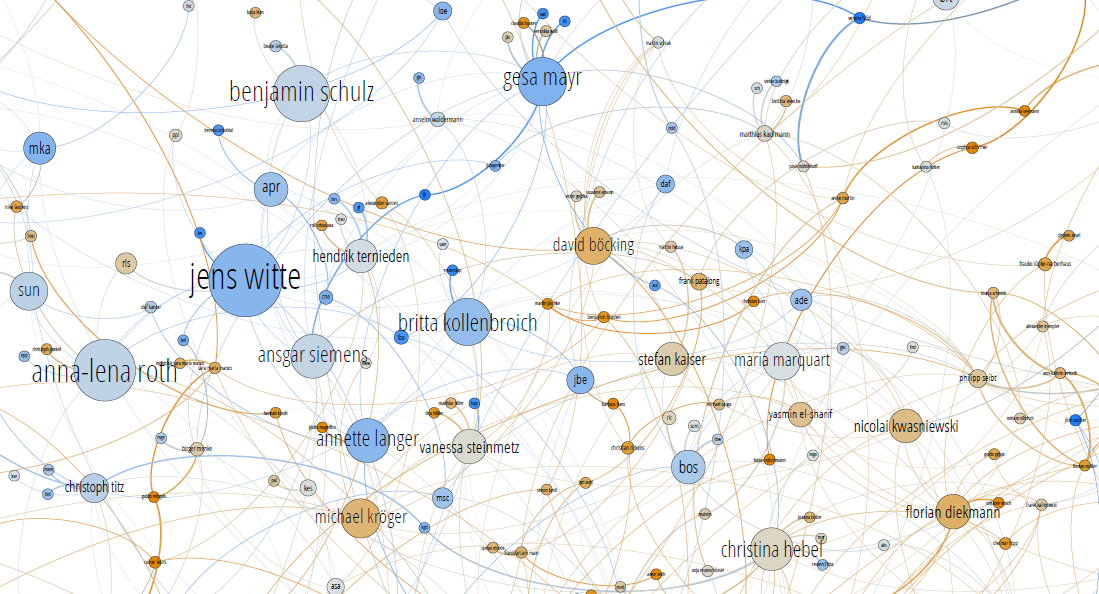
Im folgenden Bild sind die Autoren analog zum letzten Artikel nach Median-Textlänge eingefärbt. Eher rote Autoren schreiben eher längere Texte, eher blaue schreiben eher kürzere. Da kann man genau sehen, dass die Panorama-Kollegen (im Ressort-gefärbten Graph grün) hier eher blau sind, also eher kürzere Texte schreiben.
Damit ihr euch zurecht findet: Der Ausschnit zeigt den Dicken Haufen in der Mitte des obigen Bildausschnitts. Nehmt z.B. den großen Knoten mit Jens Witte als Orientierungspunkt, wenn ihr vergleichen mögt. Das ist im obigen Bild der dicke grellgrüne.
 Hier könnt ihr ein PDF mit dem vollständigen Graph herunterladen.
Hier könnt ihr ein PDF mit dem vollständigen Graph herunterladen.
Sucht doch mal nach dem Ressort Kultur im Ressortgraph (oben links, Dunkelblau) und dann guckt ihr im Textlängengraph mal, ob die wirklich alle Schwierigkeiten haben, sich kurz zu fassen, oder ob das ein härtestes Vorurteil von mir im letzten Artikel war.
Wer sind die Schlüsselfiguren?
Wenn man ein soziales Netz von außen betrachtet, ist immer interessant, wer die Schlüsselpersonen sind. Das sieht man nicht immer auf Anhieb, es sind nämlich nicht zwangsläufig diejenigen, wo „Chef“ drauf steht. Wir färben die Autoren jetzt mal danach ein, mit wievielen verschiedenen anderen Autoren sie im Beobachtungszeitraum zusammen Artikel geschrieben haben. Dunklere Farbe bedeutet mehr Partnerautoren.
![]() Hier könnt ihr ein PDF mit dem vollständigen Graph herunterladen.
Hier könnt ihr ein PDF mit dem vollständigen Graph herunterladen.
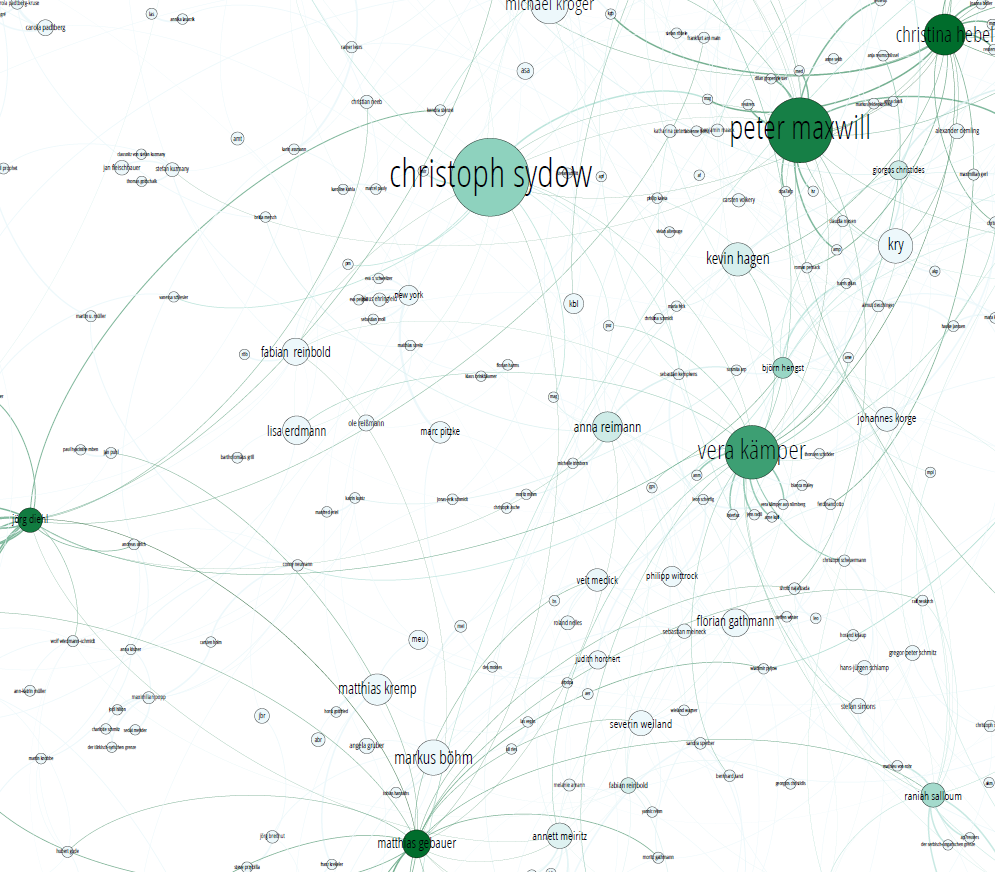
Auf anhieb stechen Peter Maxwill und Vera Kämper heraus, weil sie groß und dunkel sind. Zur Erinnerung: Die Größe der Autorenblasen gibt die Anzahl der Artikel wieder, die die Autoren im Beobachtungszeitraum geschrieben haben. Zusätzlich sind diese beiden Autoren zu besonders vielen anderen vernetzt. Sie arbeiten in den dominierenden Ressorts Panorama bzw. Politik. Offensichtlich schreiben sie aber auch besonders viele Artikel, da wäre es dann auch komisch, wenn sie die nur mit einigen wenigen anderen Autoren zusammen schreiben würden. Es ist also nicht ganz klar, wie aussagekräftig das ist – dazu gleich noch mehr.
Das führt mich zum relativ kleinen, aber trotzdem dunkelblauen Matthias Gebauer (im Ausschnitt unten mittig). Hier hat unsere Visualisierung zielsicher einen „Chefreporter“ bei Spiegel gefunden (schaut ins SpiegelImpressum – das ist irgendeine Form von Amt, aber man ist glaube ich nicht wirklich in der Führungsetage, die Chefreporter stehen separat von den Chefs vom Dienst und der Chefredaktion und auch weiter unten). Der hat im Graph auch extrem viele Nachbarn, und bei ihm kann man es nicht mal auf die schiere Artikelanzahl schieben. Auch Jörg Diehl sticht im Graph auf dieselbe Weise heraus – zack, ebenfalls Chefreporter. Wie ihr seht, kann man mit solchen Analystechniken ohne weiteres Schlüsselpersonen finden.
Nun ist das Maß, was wir genommen haben („Anzahl der Verbindungen zu anderen Autoren“) durchaus etwas oberflächlich. Damit kann man Leute finden, die um sich herum viele andere Leute versammelt haben. Das heißt aber noch nicht, dass die innerhalb der Organisation an guten Stellen sitzen. Theoretisch könnten die auch eine Masse um sich versammelt haben, aber der ganze Haufen samt dunkel eingefärbter Zentralperson sitzt irgendwo in der Peripherie. Ein Beispiel für so ein Phänomen ist der Chef von Pegida. Der hat zigtausend Anhänger, sieht bei lokaler Betrachtung also extrem gut vernetzt aus. Aber die ganze Gruppierung ist irgendwo dort, wo ihr keiner zuhört, und darum ist es ganz egal, wieviele Zuhörer der Chef davon hat.
Umgekehrt kann ein Autor nur wenige Verbindungen haben, aber das Verbindungsstück zwischen zwei Hälften einer riesigen Organisation sein. Darum nehmen wir jetzt mal ein globaleres Maß: Die Betweenness Centrality. Die rechnet man grob gesagt so aus:
- Man misst für jeden Autor den kürzesten Weg zu jedem anderen Autor entlang der Verbindungen
- Autoren, die auf möglichst vielen solcher kürzesten Wege liegen, sind Schlüsselpositionen und damit „wichtig“.
 Hier könnt ihr ein PDF mit dem vollständigen Graph herunterladen.
Hier könnt ihr ein PDF mit dem vollständigen Graph herunterladen.
So sieht das ganze dann aus. Zunächst mal treten wieder die Personen hervor, die wir eben schon genannt haben. Hinzu kommt aber z.B. Christina Hebel im Ressort Politik (rechts über Peter Maxwill). Die war im letzten bild zwar auch schon eher dunkel als hell, aber jetzt hat sie die anderen im Bild überholt! Sie bekleidet kein spezielles Amt, ist aber insgesamt auffällig, vielleicht wird das also bald. Behaltet sie mal wohlwollend im Auge. Spitzenreiter ist übrigens hier der oben schon genannte Chefreporter Matthias Gebauer. Ein weiterer vergleichsweise dunkler Punkt ist Christina Elmer (nicht im Bild, sucht im PDF). Sie hat offiziell keine Cheffunktion, aber dennoch gehen viele kürzeste Pfade über sie. Sie arbeitet im Bereich des Datenjournalismus, also muss ich schon aus verschwörungstheoretischen Gründen annehmen, dass sie ihre Stelle mit voller Absicht auf die Betweenness Centrality hin optimiert hat!
Übrigens hat die Zentralität eines Autors übrigens nichts damit zu tun, ob er in irgendeiner Form der Chefetage angehört. Im folgenden Graph sind die Chefredakteure, Mitglieder der Chefredaktion, sowie die Chefs vom Dienst rot eingefärbt, und der ganze Rest grau.
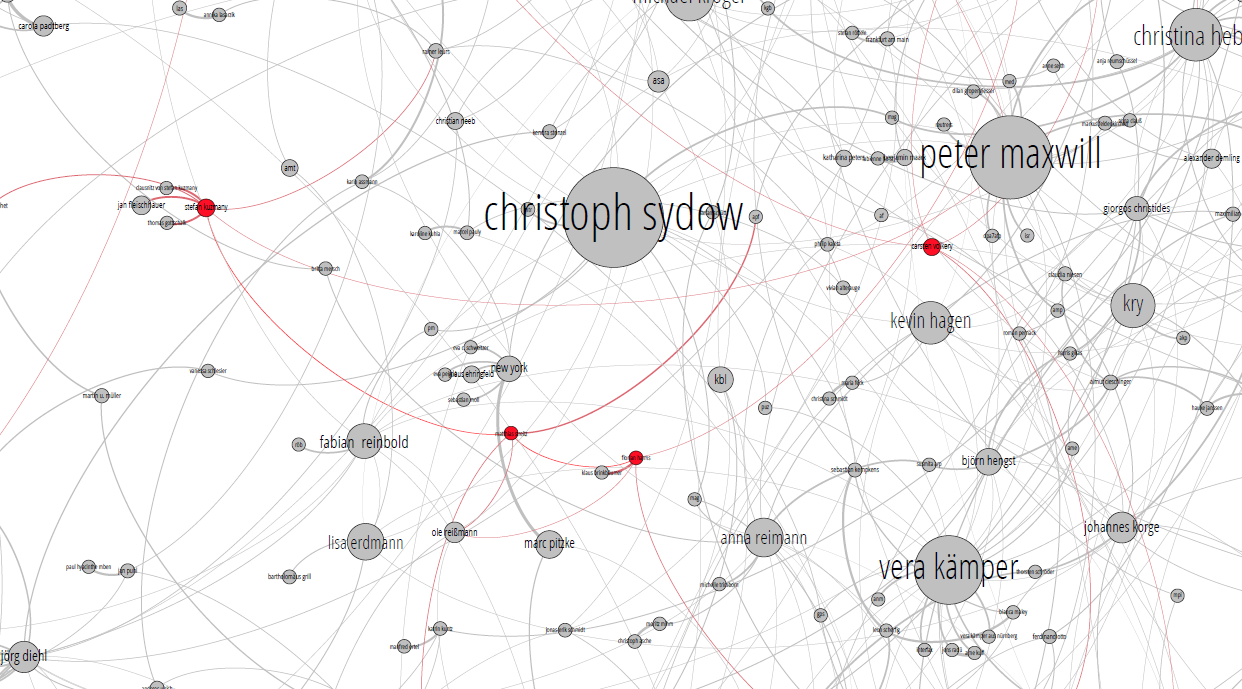 Hier könnt ihr ein PDF mit dem vollständigen Graph herunterladen.
Hier könnt ihr ein PDF mit dem vollständigen Graph herunterladen.
Resultat: Man erkennt die kaum. Kleine rote Flecken, die wir vorher auch nicht auf der Karte hatten. Was immer die Chefetage beim Spiegel so macht, auffällig gut vernetzt, was die Zusammenarbeit mit anderen in Artikeln angeht, ist sie jedenfalls nicht. Entweder schreiben sie also ihre Artikel grundsätzlich alleine, oder die Aufgaben sind ganz vom Artikelschreiben weggerückt.
Ganz anders waren dagegen die „Chefreporter“ (die ich hier nicht zur rot gefärbten „Chefetage“ gezählt habe). Die haben zwar auch weniger geschrieben als andere, aber deren extrem gute Vernetzung war ja durchaus herausgetreten in unseren Graphen. Vielleicht mag uns einer vom Spiegel mal über die unterschiedlichen Ämter aufklären, damit wir uns einen Reim drauf machen können.
Das war mal eine kleine Demo, was mit Graphen alles geht. Insbesondere haben wir gelernt, dass es nichts mit der Artikelanzahl und nichts mit dem formalen Status zu tun haben muss, wie zentral die Position eines Autors im Netzwerk der Artikelpartnerschaften ist. Man kann bei Graphen noch viele weitere Maße betrachten und auf viele weitere Weisen Graphen generieren, und seid darauf gefasst, dass wir das in den weiteren Artikeln auch tun werden, und das nicht nur an den Autoren.
Jetzt aber mal kurz Schluss mit dem dienstlichen – könnt ihr euch auch vorstellen, dass man was privates aus den Artikeldaten rauslesen kann?
... und das geht auch mit Privatstrukturen :-)
Hier seht ihr mal einen Plot von ein paar Autoren, wann sie im Messbereich veröffentlicht haben. Eine Zeile pro Autor, und nach rechts in der Zeile vergeht die Zeit. Die verschiedenen Farben markieren verschiedene Rubriken der Veröffentlichung.
 Wie immer: Draufklicken zum Vergrößern!
Wie immer: Draufklicken zum Vergrößern!
Man kann daran gut zeitliche Regelmäßigkeiten erkennen: Schaut mal bei Jan Fleischhauer, das ist ein Kolumnist, der veröffentlicht genau wöchentlich. Es sind noch zwei andere Kolumnisten abgebildet. Findet ihr sie? Auch Vorlieberessorts von Autoren und sehr interdisziplinäre (=bunte) Autoren sind auf Anhieb sichtbar.
Man kann auch erkennen, dass z.B. bei Gregor Peter Schmitz irgendwann März 2015 der Artikelstrom abrupt endet – mit anderen Worten: Er ist gegangen (kurze Internetrecherche ergibt: Der ist jetzt bei der Wirtschaftswoche, Zeitpunkt passt auch genau). Wir könnten also mal messen, ob bei SpiegelOnline die Personalfluktuation in letzter zeit zunimmt, was ein guter Indikator für das Arbeitsklima dort wäre.
Aber jetzt zum eigentlichen Punkt: Insbesondere sieht man auf dem Bild auch, wann die Autoren Urlaub machen. Das sind nämlich die Lücken in den Zeilen. Man kann auch Ende Dezember 2015 eine übergreifende Feiertagspause erahnen (eine etwas freiere vertikale Spalte ist sichtbar). Lasst euch nicht von der freien Spalte im März 2015 irreführen: Wie im letzten Artikel schon gesagt, habe ich da einige wenige Tage aufgrund eines Bugs keine Spiegelartikel heruntergeladen.
Ich appelliere nun an eure Berufserfahrung und mutmaße mal ganz wild, dass auch ihr schon mal Kollegen hattet, die … irgendwie immer gleichzeitig im Urlaub waren. Merkt ihr was?
Man markiere also die längeren Zeiträume, über die ein Redakteur weg ist. Am besten lässt man nur Abwesenheiten ab 10 Tagen gelten, sonst kriegt man alle Wochenenden mit Brückentagen angezeigt. Sobald man das Muster der mutmaßlichen Urlaubstage für jeden Autor hat, vergleicht man die diese Muster unter den Autoren und baut genau so einen Graph, wie ich das oben gemacht habe – nur dass die Verbindungen zwischen den Autoren diesmal aussagen, dass zwei Autoren auffällig oft gleichzeitig weg sind. Das ist natürlich in dem Fall etwas unscharf, weil man Artikel auch terminieren kann und dadurch Tage als „Anwesend“ gekennzeichnet werden, bei denen man eigentlich im Urlaub war. Das heisst, dass wir mit etwas verrauschten Vergleichswerten zu rechnen haben und darum von Hand noch mal über die Ergebnisse gucken müssen, aber das ist eigentlich sowieso immer der Fall – den Plausibilitätscheck mit dem eigenen Gehirn ersetzt auch in der DataScience nichts.
Insgesamt kann man so eine Landkarte erhalten, die im Analysten-Fachjargon „Schlampengraph“ genannt wird.  Wir machen das jetzt hier aber nicht, denn es ist nicht mein Ziel, persönliche Sachen über Leute öffentlich zu machen – aber ich weise ganz ausdrücklich darauf hin, dass sowas geht, und zwar wiederum nur durch Metadaten.
Wir machen das jetzt hier aber nicht, denn es ist nicht mein Ziel, persönliche Sachen über Leute öffentlich zu machen – aber ich weise ganz ausdrücklich darauf hin, dass sowas geht, und zwar wiederum nur durch Metadaten.
Liebe geheime Spiegelliebespaare, ihr dürft jetzt wieder ausatmen und müsst keine Angst haben, hier geoutet zu werden (ich verlange aber, bei der Hochzeit ein Bier ausgegeben zu kriegen)! Und von der Person mit 5 Verbindungen gleichzeitig wüsste ich gerne, wie sie das managt.
Und liebe Leser, ihr habt heute gelernt: Man kann auch aus Metadaten extrem viel herauslesen. Wenn ich ein paar eurer Kommunikationsmetadaten habe (mit wem ihr mailt oder SMSt, ohne Inhalte) kann ich euch mit hoher Wahrscheinlichkeit sagen, ob ihr schwanger seid, eine Krankheit habt, verliebt seid, Kinder habt, oder sonst was. Also lasst euch nix erzählen, wenn jemand kommt und sagt „Och, sind doch nur Metadaten“. Ich brauche keine tatsächlichen Inhaltsdaten, um wirklich private Dinge über euch und eure Einsortierung in euer Umfeld zu erfahren. Und jetzt versteht ihr vielleicht auch, warum manche Leute gegen die Vorratsdatenspeicherung was haben. Hier ein Artikel zum weiterlesen.
Na dann, bis zum nächsten mal – und bleibt mir gewogen!
Macht mit!
Ich mache auch noch mal darauf aufmerksam, dass ihr mir gerne Auswertungsideen schicken könnt. Die Artikelserie ist durchaus so gedacht, dass sie auch von euch lebt. Schon klar, das geht natürlich besser, wenn ihr wisst, was für Merkmale ich schon erfasse und was ich so für Auswertungen betreibe. Aber das wird ja langsam. Also lasst euch inspirieren.
1)
wundert ihr euch über den Namen Drumpf? So leset hier und freuet euch!