
Wahl-O-Mat-Auswertung Bundestagswahl 2017, Teil 2: Thesen- und Parteienverwandtschaften
 Heute geht es noch mal ein bisschen um den Wahl-O-Mat. Wie letztes mal werte ich die Parteien nach ihren Antworten auf die Wahl-O-Mat-Thesen aus, aber diesmal rendere ich daraus keine Landkarte, sondern eine Cluster Heatmap. Diese Art der Grafik ist etwas komplexer. Dafür ist sie sehr Informationstragend. Ich präsentiere sie wieder zuerst, und danach führe ich euch schrittweise heran. Wie immer könnt ihr die Grafik zum Vergrößern klicken.
Heute geht es noch mal ein bisschen um den Wahl-O-Mat. Wie letztes mal werte ich die Parteien nach ihren Antworten auf die Wahl-O-Mat-Thesen aus, aber diesmal rendere ich daraus keine Landkarte, sondern eine Cluster Heatmap. Diese Art der Grafik ist etwas komplexer. Dafür ist sie sehr Informationstragend. Ich präsentiere sie wieder zuerst, und danach führe ich euch schrittweise heran. Wie immer könnt ihr die Grafik zum Vergrößern klicken.
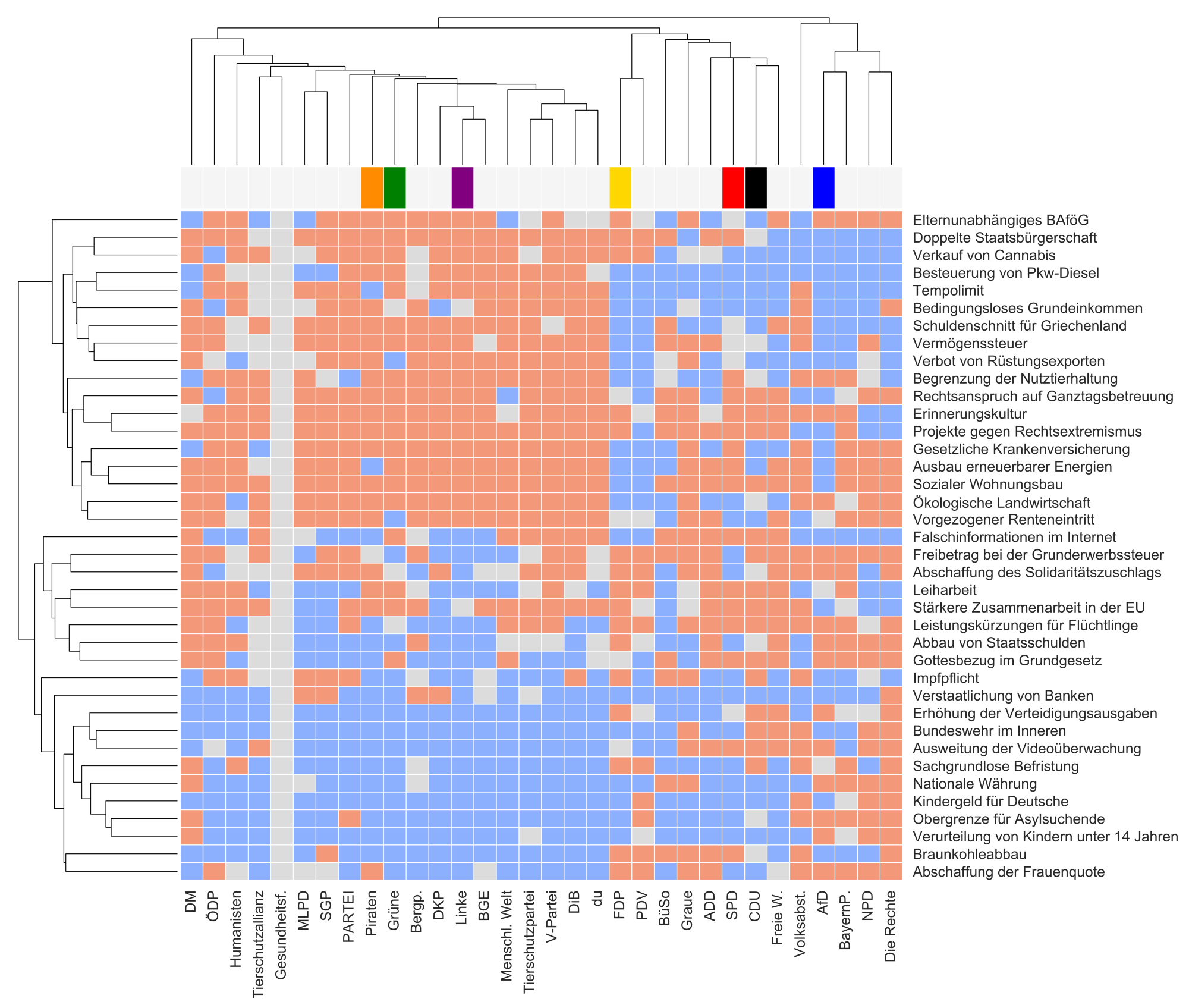
Was also sehen wir hier? Der Kern der Grafik, das große rotblaue Rechteck, ist eine sogenannte Heatmap. Das ist nichts weiter, als die farbliche Darstellung einer Tabelle.
Zeilen, Spalten, Heatmap
Die Zeilen der Tabelle sind die 38 Thesen des Wahl-O-Mats (damit ihr euch nicht durchklicken müsst: Die Thesen gibt es hier). Die Spalten sind die Parteien. Thesen sind rechts beschriftet, Parteien unten. Über dem großen Rechteck findet ihr bei den bekannteren Parteien noch deren Farbe.
Das große blaurotgraue Rechteck in der Mitte sind nun die Antworten der jeweiligen Parteien zu den jeweiligen Thesen. Rot ist Zustimmung, Blau ist Ablehnung, Grau ist Neutralität. Man kann sehr schön sehen, dass die Gesundheitspartei (5. von Links) überall neutral abgestimmt hat. Das war auch schon die Heatmap, die könnt ihr jetzt lesen.
Gruppierung der Parteien
Jetzt ist euch bestimmt schon aufgefallen, dass sowohl die Thesen, als auch die Parteien keine Ordnung haben, die man auf Anhieb versteht. Auf den ersten Blick scheinen die „irgendwie“ durcheinandergewürfelt zu sein.
Des Rätsels Lösung ist: Sowohl Thesen als auch Parteien sind –grob! – nach Ähnlichkeit geordnet! Zwei Parteien sind ähnlich, wenn ihre Antworten auf die Thesen sich gleichen (in der Heatmap sind das ähnliche Spalten). Und das geht auch andersrum: Zwei Thesen sind einander ähnlich, wenn sie von den gleichen Parteien gemocht bzw. nicht gemocht werden (das sind dann ähnliche Zeilen).
Wir schauen uns erstmal die Reihenfolge der Parteien an. Die haben sich anscheinend automatisch nach ihrer politischen Richtung angeordnet (ja, automatisch, das ist nicht mein Werk, und das ist das interessante daran!).
Die fünf linkesten Parteien waren durch den Algorithmus nicht so gut einzusortieren. Ich nenne sie „die Eigensinnigen“. Dazu gehört die gut sichtbare Gesundheitspartei, die alle Thesen neutral angekreuzt hat. Danach folgt der riesige, anscheinend links ausgerichtete Parteiblock, den wir schon im letzten Artikel gesehen hatten.
Diese Gruppe Parteien ist in sich sehr, sehr homogen. Im Wesentlichen mögen sie alle die oberen Thesen, darum ist da alles rot. Und sie lehnen die unteren Thesen ab, darum ist da alles blau.
Rechts vom der homogenen Gruppe kommen die Parteien der Mitte (FDP, SPD, CDU) und alle drumherum, wobei ich die CDU hier als rechte Grenze sehe. Die erste Partei rechts vom Linken Block ist hier interessanterweise die FDP (leicht abweichend von unserer Graphik aus dem letzten Artikel, aber dazu was hier die Abstände zwischen den Parteien sind, kommen wir noch).
Es folgt die Partei der „Volksabstimmung“, war wohl nicht so dolle einzusortieren, dazu später mehr. Und danach folgen die vier rechten Parteien. Hier kann man wieder unterteilen, dass erst die „eher rechten“ Parteien BP und AfD kommen, und danach die noch extremeren. BP und AfD waren auch im letzten Artikel schon sehr verwandt.
Gruppierung der Thesen
Jetzt zu den Thesen. Wir sehen den riesigen roten, fast massiven Block oben links in der Heatmap. Links sind die anscheinend links ausgerichteten Parteien, und rot ist Zustimmung. Ich wiederhole noch mal: Die Ausrichtungen der Parteien wurden hier nur an der Antwort auf die Wahlomatthesen vermessen, das ist alles unscharf (wenn auch interessant). Diese Thesen scheinen also alles linke Herzensangelegenheiten zu sein, wohingegen bei den linken Parteien unten fast alles blau ist, also abgelehnt wird. Wir machen mal ein paar Stichproben.
Die Linken mögen fast übergreifend die Doppelte Staatsbürgerschaft, Dieselbesteuerung, Tempolimit, Bedingungslose Grundeinkommen, Schuldenschnitt für Griechenland, das ausnahmslose Verbot von Rüstungsexporten, Vermögenssteuer, Projekte gegen Rechtsextremismus, sozialen Wohnungsbau, und noch ein paar andere Sachen. Scheint echt zu passen.
Der Witz ist, dass in diesem homogenen roten Block Ausnahmen sofort sichtbar sind. Das können wir jetzt nutzen, um mittels fiesesten Vorurteilen etwas Ketzerei zu betreiben. So sind zum Beispiel ausgerechnet die Grünen gegen ein ausnahmsloses Exportverbot von Rüstungsgütern. I shit you not, schaut selbst.  (Sicher gibt es dafür Beweggründe, ihr könnt auf der Wahl-O-Mat-Seite in den Thesenbegründungen nachlesen, warum jede Partei wie abgestimmt hat.)
(Sicher gibt es dafür Beweggründe, ihr könnt auf der Wahl-O-Mat-Seite in den Thesenbegründungen nachlesen, warum jede Partei wie abgestimmt hat.)
Die Grünen sind auch gegen den vorgezogenen Renteneintritt als eine der ganz wenigen unter den linken Parteien. Böswillige Menschen würden sich hier an das Zitat von Westerwelle erinnern: „Die eine Hälfte der Grünen ist beim Staat angestellt, die andere Hälfte lebt vom Staat.“ – dafür ist es zwangsweise erforderlich, dass die andern länger arbeiten.
Die Piraten sind gegen generelle Tempolimits, was auch herrlich dem Klischee einer Partei mit eher jüngeren Mitgliedern entspricht. Und die Kommunisten sind gegen ein bedingungsloses Grundeinkommen.
Hier links verortete Parteien mögen fast übergreifend nicht: Sachgrundlose Befristung von Arbeitsverträgen, den Abbau von Staatschulden, eine Obergrenze für Asylsuchende. Auch plausibel.
Die anderen Parteien sind insgesamt ein weniger homogener Block, darum können wir da weniger lustige Ausreißer finden. Schade. Ich hätte gerne auch die andere Seite etwas ketzerisch aufs Korn genommen. Tobt euch aber gerne in den Kommentaren aus. Homogen ist vor allem eine These: Die gesamten nicht-linken Parteien wollen keine höhere Dieselbesteuerung, fast alle linken Parteien schon.
Egal, genug vorgekaut, schaut euch selber an. Was wir noch nicht besprochen haben, ist, wie das Gruppieren funktioniert (diese Section ist für die technischer interessierten unter euch).
Hierarchical Clustering
Die Gruppierungsmethode hier heißt Hierarchical clustering, und wie der Name schon sagt, erstellt sie eine Hierarchie von Gruppen. Ineinandergeschachtelte Gruppen, sozusagen. Beispiel Parteien: Die Menge aller Parteien wird erstmal in zwei geteilt, und zwar mathematisch so, dass die beiden neu entstandenen Teilgruppen in sich möglichst homogen, also einander ähnlich sind (im Abstimmungsverhalten bezüglich der Thesen). Mit den Teilgruppen wird das dann wieder gemacht, und so weiter und so fort, bis jede Gruppe nur noch eine Partei stark ist.
Die entstandene hierarchische Gruppenstruktur wird durch die Bäume im Bild angezeigt. Oben ist der Baum für die Parteien, und links der für die Thesen. Wir beginnen mit dem Baum oben, der die Parteiordnung vorgibt. Wir bilden den hier mal zur Erklärung im Detail ab:
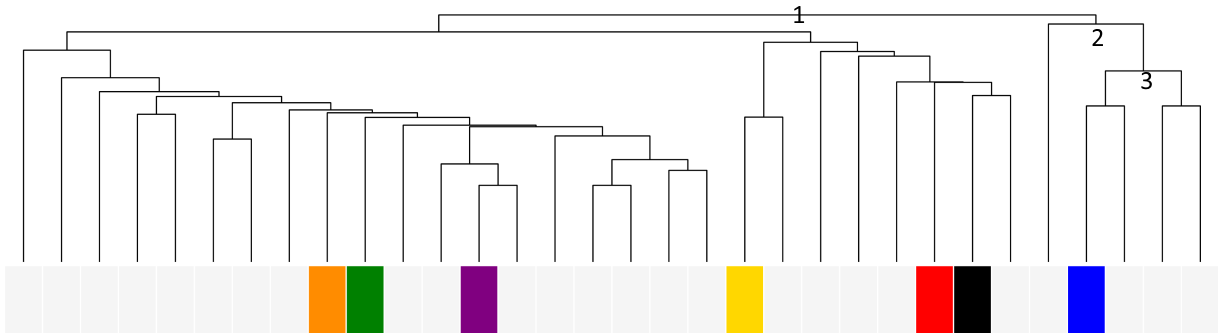
Wir sehen , dass die alleroberste Verästelung (nennen wir mal Split 1 – im Detailbild mit 1 gekennzeichnet) zwei Untergruppen produziert. In einer Gruppe sind alle eher rechten Parteien, und in der anderen Gruppe der ganze Rest: Mitte und Linke Parteien. Der Algorithmus findet also: Die mittleren Parteien sind den linken Parteien näher als den rechten. Schon mal interessant.
Betrachten wir nun die rechte Gruppe. Diese wird wieder in zwei gespalten (Split 2, ebenfalls im Detailbild nummeriert). Wie man am Baum sieht, wird die Volksabstimmungspartei als einzige abgespalten, und die rechteren und rechtsextremen Parteien bleiben beieinander. Wenn direkt so früh des Abspaltungsvorgangs im Abspaltungsvorgang einzelne Elemente abgespalten werden, kann das heißen, dass die Partei nicht gut einzuordnen war, und in der Tat ist die Volksabstimmungspartei eine der eigensinnigen. Die andere neu entstandene Teilgruppe aus Split 2 sind dann wirklich die vier rechten Parteien.
Generell gilt: Je tiefer Parteien voneinander getrennt werden, desto ähnlicher sind die sich. Parteien, die früh getrennt werden, sind nur in sehr weitgefassten Gruppen zusammen.
Diese Gruppe der vier rechten Parteien wird dann wieder gesplittet (Split 3), und heraus kommen wieder zwei Gruppen: Die Parteien AfD und BP und die Parteien NPD und die Rechte. Beide Zweiergruppen werden dann später noch mal zu Einergruppen geteilt.
Kommen wir zum riesigen linken Teilast, der bei Split 1 entstanden ist. Da läuft es genauso, den gehen wir etwas schneller durch. Zunächst enthält der Teilast die Gruppe der „Linken und Mitte“-Parteien, und ein paar eigensinnige sind wieder enthalten. Als erstes abgespalten wird die „Mitte“ von dem großen Block der „linken und eigensinnigen“. Die Mitte enthält unter anderem FDP, SPD, und CDU.
Der Baum, der die Thesen splittet, funktioniert genauso. Die verschiedenen ober und Untergruppen werden zueinander layoutet, und so ergibt sich eine einigermaßen schlüssige Ordnung der Thesen, wobei es hier genau andersrum ist: Thesen sind ähnlich, wenn die gleichen Parteien für oder gegen sie stimmen.