News
Sonntagsfragen-Update 2023 / Anfang 2024
 Angesichts der hervorragenden politischen Stimmung habe ich meine garantiert unaufgeregte Sonntagsfragen-Auswertung mal auf die Aufnahme neuer Parteien vorbereitet und verschiedene Features hinzugefügt.
Angesichts der hervorragenden politischen Stimmung habe ich meine garantiert unaufgeregte Sonntagsfragen-Auswertung mal auf die Aufnahme neuer Parteien vorbereitet und verschiedene Features hinzugefügt.
Der größte Punkt ist eine Schlagseitenanalyse für alle Institute - bei welchem Institut kommt welche Partei besonders gut weg? (Erklärung und eine Vielzahl von Charts auf der Seite selbst.)
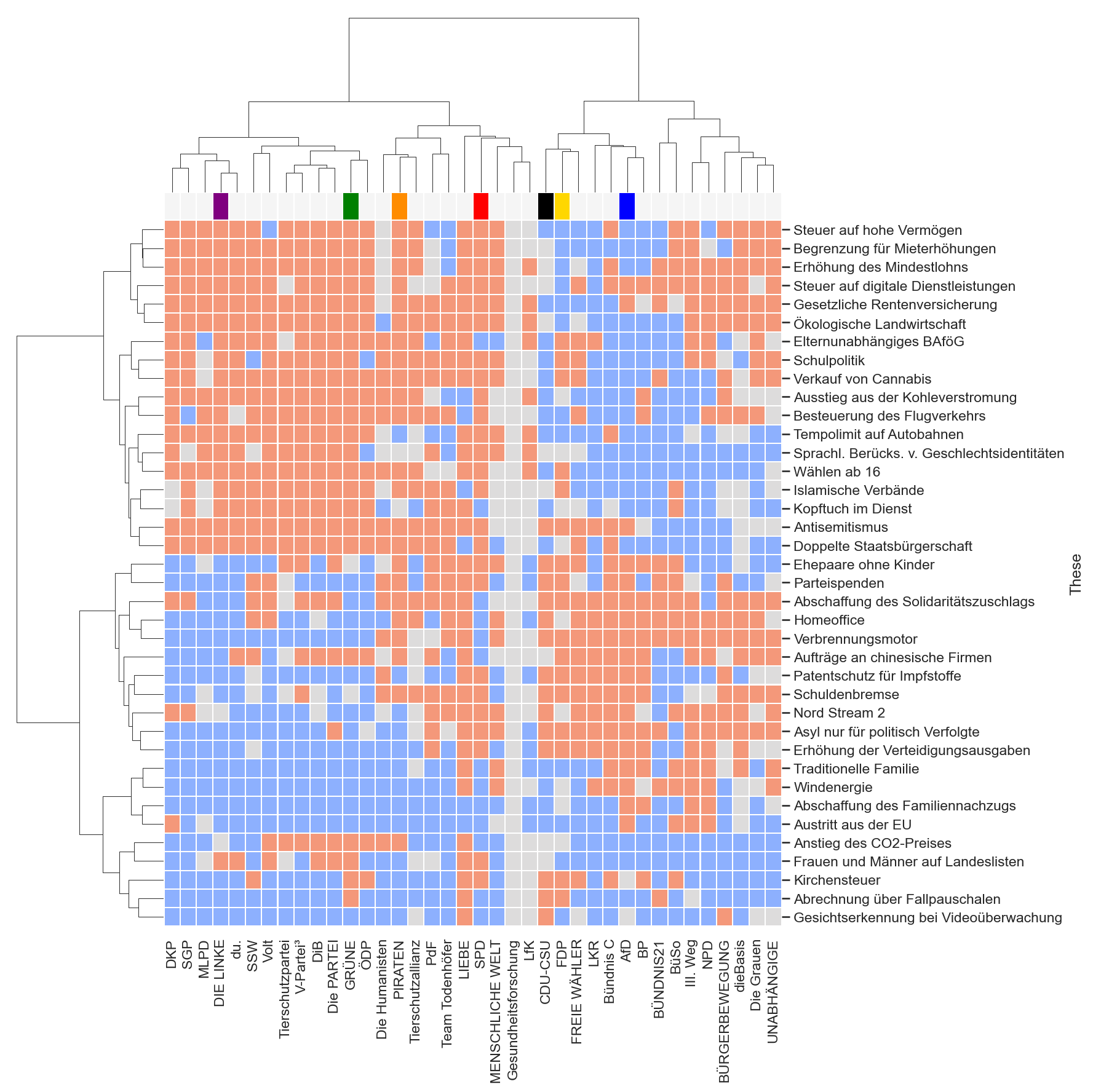
Neu sind auch Hilfslinien für die Nachverfolgung der Datenpunkte der aktuellst geupdateten Institute in die Detail-Plots (sieht man hier direkt im Plot unter diesem Text). So kann man direkt gucken, ob diese aktuellsten Datenpunkte im Vergleich zu ihren Vorgängern bei demselben Institut gestiegen oder gesunken sind.
Es sind jetzt auch die Bundestagswahlen seit 1998 markiert. Dieser Wunsch kommt schon seit drölf Jahren von etlichen Benutzern, ich war aber nie dazu gekommen. Sorry.
Seit fast sieben Jahren führe ich nun diese Analyse auf meiner Webseite, und seit ein paar wenigen Jahren gibt es sowas auch auf verschiedenen Kwalitätsmedien. Auch wenn ich das nicht beweisen kann, hoffe ich natürlich ein klein wenig, daran Schuld zu sein und will den Maßstab hoch halten 
Edit: Hab mich noch mal drangesetzt, die Freien Wähler sind jetzt drin, wo die Institute es offiziell (und nicht nur als Teil der „Sonstigen“) hergeben. Dafür sind die „Sonstigen“ rausgeflogen, wurde unübersichtlich bei wenig Informationsgewinn.
Nachtrag 02.02.2024: BSW jetzt auch drin. Farben angepasst. Code angepasst, so dass er auch die neuen Parteien abgreift, wenn diese als Mehrfachzellen in die Snstigen hineingewurstet sind.
Corona-Plots: Neujahrs-Update 2022
 Es gibt wieder ein Neujahrs-Update zu meinen Corona-Plots unter http://www.dkriesel.com/corona. Der kumulative Plot ist jetzt ein Active-Cases-Plot geworden, weil das aus heutiger Sicht interessanter ist. Die Gesamtzahlen der Toten und Genesenen finden sich jetzt einfach im Untertitel. Im täglichen Plot sind die Y-Achsen jetzt umgekehrt, da die Active Cases bei Omikron interessanter sind als die viel spärlicher vorhandenen Tode. Der Impfplot enthält jetzt Boosterimpfungen und ist auf 90% der Bevölkerungsgröße des jeweiligen Landes normalisiert, damit man auf einen Blick sehen kann, ob ein Land mit den Impfen gut oder schlecht dabei ist. Viel Spaß!
Es gibt wieder ein Neujahrs-Update zu meinen Corona-Plots unter http://www.dkriesel.com/corona. Der kumulative Plot ist jetzt ein Active-Cases-Plot geworden, weil das aus heutiger Sicht interessanter ist. Die Gesamtzahlen der Toten und Genesenen finden sich jetzt einfach im Untertitel. Im täglichen Plot sind die Y-Achsen jetzt umgekehrt, da die Active Cases bei Omikron interessanter sind als die viel spärlicher vorhandenen Tode. Der Impfplot enthält jetzt Boosterimpfungen und ist auf 90% der Bevölkerungsgröße des jeweiligen Landes normalisiert, damit man auf einen Blick sehen kann, ob ein Land mit den Impfen gut oder schlecht dabei ist. Viel Spaß!

Corona-Inzidenzen nach Impfquote, pro Kreis
Diese Daten sind von Anfang Dezember 2021 und damit outdated.
Für die politische Ebene völlig überraschend befinden wir uns in der 4. Coronawelle und haben zum Glück darauf geachtet, noch vor dem Herbst die Impf- und Testkapazitäten zurückzufahren. Das gibt uns die Gelegenheit zu einer interessanten Auswertung: Man errechne die allgegenwärtigen 7-Tage-Corona-Inzidenzen für jeden Land-/Stadtkreis, und halte sie gegen die Quote der Vollgeimpften für jeden Kreis (alle Datenquellen am Ende des Artikels). Es kommt das folgende Bild heraus (Klick zum Vergrößern):
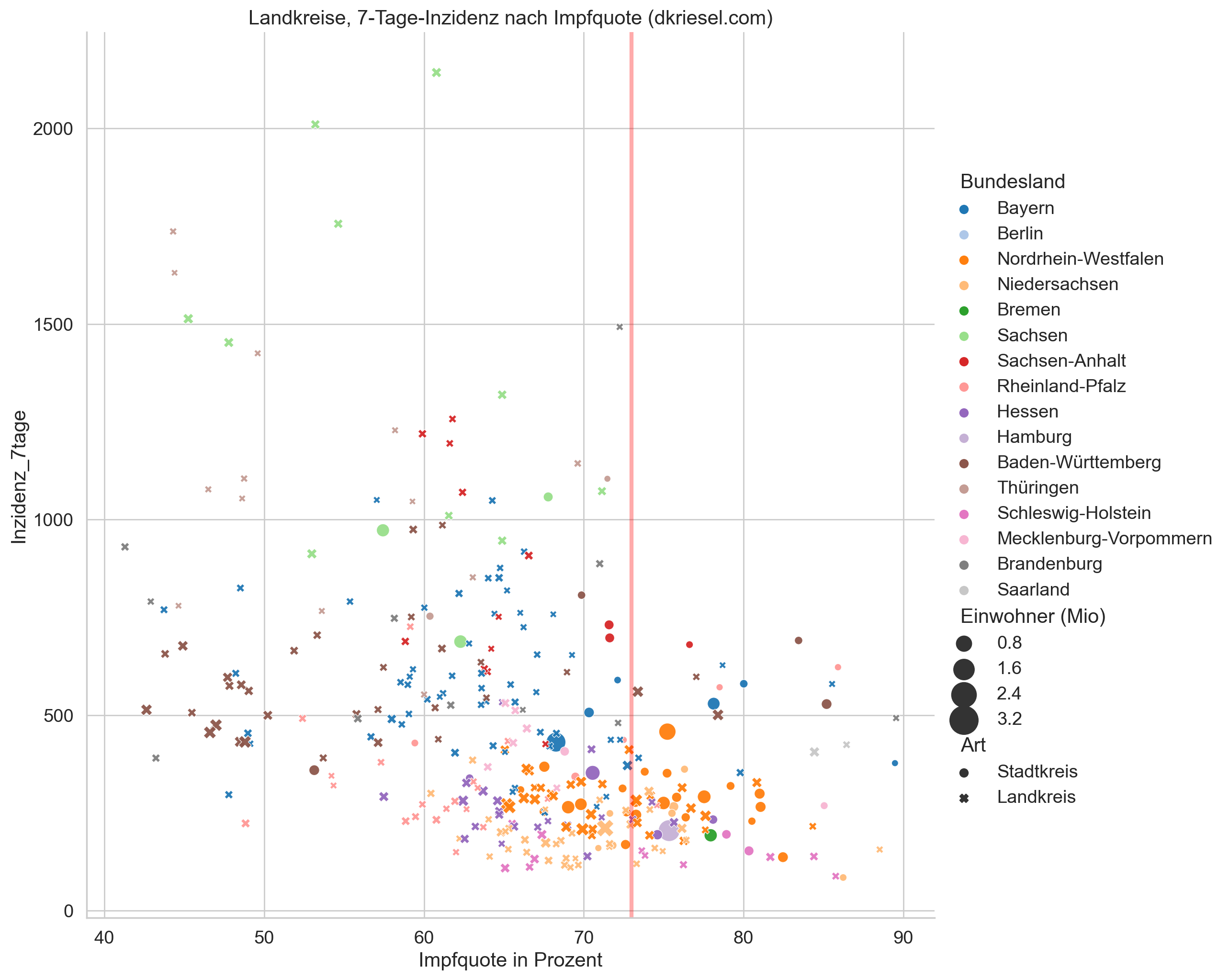
Wie immer erhaltet ihr von mir einen ausführlichen Beipackzettel, der die Ergebnisse und die Unsicherheiten enthält. Ich fange mit den Unsicherheiten an.
Wahl-O-Mat-Auswertung Bundestagswahl 2021, Teil 2: Thesen- und Parteienverwandtschaften
Nach der Parteienlandkarte gibt es auch dieses Jahr einen zweiten Teil der Wahl-O-Mat-Auswertung mit der ebenfalls schon aus 2017 bekannten Cluster Heatmap, die sowohl eine Analyse von Parteinachbarschaften, als auch von verwandten Thesen (=ähnliches Parteizustimmungsmuster) zulässt. Diese Art der Grafik ist sehr Informationstragend. Ich präsentiere sie wieder zuerst, und danach führe ich euch schrittweise heran.