Table of Contents
Xerox scanners/photocopiers randomly alter numbers in scanned documents
Please see the “condensed time line” section (the next one) for a time line of how the Xerox saga unfolded. It for example depicts that I did not push the thing to the public right away, but gave Xerox a lot of time before I did so. Personally, I think this is important. I will post updates and links to the relevant blog posts in there in order not to make total crap out of this article's outline. In this way, I keep this article up-to-date for future visitors and also write new blog posts on the topic for RSS users.
Video of my Talk "Lies, damned lies and scans"
This FrOSCon Talk (August 2015) is a native english version of the quite popular CCC talk (December 2014), so I embed this instead of the live translation by CCC.
Here you can download the slides.
Here you can send me feedback on the talk! Thank you! 
Introduction
In this article I present in which way scanners / copiers of the Xerox WorkCentre Line randomly alter written numbers in pages that are scanned. This is not an OCR problem (as we switched off OCR on purpose), it is a lot worse – patches of the pixel data are randomly replaced in a very subtle and dangerous way: The scanned images look correct at first glance, even though numbers may actually be incorrect. Without a fuss, this may cause scenarios like:
- Incorrect invoices
- Construction plans with incorrect numbers (as will be shown later in the article) even though they look right
- Other incorrect construction plans, for example for bridges (danger of life may be the result!)
- Incorrect metering of medicine, even worse, I think.
The errors are caused by an eight (!) year old bug in widely used WorkCentre and ColorQube scan copier families of the manufacturer Xerox – according to reseller data, hundreds of thousands of those machines are used across the planet. As a result, anyone having used machines of the named families has to ask himself:
- How many incorrect documents (even though they look correct!) did I produce during the last years by scanning with xerox machines? Did I even give them to others?
- What dangers are imposed by such possible document errors? Is there a danger of life for someone?
- Can I be sued for such errors?
Before the bug was covered in my blog, it was not discovered or published, nor was its montrosity visible to Xerox or me. It unleashed itself across several blog articles I wrote that were then spread further by the mass media. What happened in which order can be seen in the time line below. It has been an interesting time, I promise. Originally, this blog article was published in the fear the bug would be dangerous enough to put lifes at risk and in the believe Xerox would not take the bug report serious.
The rest of the article is organized as follows.
- First, there is a time line for you to see how the saga unfolded
- By showing some real world examples I outline how we got aware of the issue, and how subtle it is. As it is hard to believe that scan copiers randomly alter written numbers, picture evidence is provided.
- After that, there is a list of affected devices.
- In the next section, there is a a short manual for you to reproduce the error and see of you are affected.
- The last section contains a short, amateurish legal evaluation. Upshot: The last 8 years of PDF scans of affected devices may not only contain arrors, but also I think they might be of no legal value alltogether, regardless if they are actually proven to contain errors.
Condensed time line
Due to the mass of the blog articles, I keep getting asked for a comprehensive time line. Here it is. The relevant blog posts are linked (barely visible, though, hm). This list will be updated as used, the current status is always marked with a  .
.
| Date | What happened |
|---|---|
| July 24th, 2013 | Number mangling discovered |
| July 25th | Told Xerox about number mangling in pixel data. During the next days, neither the Xerox support levels we had phoned, nor the Xerox helpdesks visiting, did know that character substitutions could occur at all and were amazed to see this. The Xerox helpdesk guys even set out replicating the “bug” at their devices and managed to do so. I think this is important as it depicts that I first went to Xerox and gave them about a week of time, before I posted it on my blog. Later I was to learn that the number mangling was known to Xerox. |
| August 1 | No solution from Xerox yet, nearly one week, across all support levels. They either do not believe us or look amazed. I think this is scary and write this blog post. |
| August 2 | The blog post goes around the planet. From now on, I get emails of people being able to replicate the “bug” around the world, as well as informations that JBIG2 compression can cause this. I update this blog post a lot. |
| August 6, morning | A reader tells me there is a small notice in his copier's admin panel about character substitution. On his device, the “bug” can be avoided by setting compression from “normal” to higher. As a consequence, the issue must have been known by Xerox – so why was nobody telling us? As the notice only occurs when adjusting the setting in the admin panel, the implications, however, stay the same. People may create false figures without knowing. Anyway, I write a blog post presenting this workaround. |
| August 6, afternoon | Conference call with Rick Dastin and Francis Tse. Rick Dastin, Vice President at Xerox, is the first one actually working at Xerox being able to tell me that character substitutions actually can occur and Xerox knows (in contrast to their support). They also tell me that this is wanted. I criticize that this compression mode is called “normal”. I also learn that there are two notices in the (300 page) manuals also, telling about character substitution, also with respect to “normal”. |
| during the conference call | Xerox publishes their first press statement. “For data integrity purposes, we recommend the use of the factory defaults with a quality level set to “higher.”” Aside from this, they confirm the work around and tell the customers about the small notice. |
| August 7 | Second Statement, Software patch announced, reads like the “normal” setting will be entirely eliminated by the patch. Xerox states most clearly: “You will not see a character substitution issue when scanning with the factory default settings.” In a further document, these factory settings are defined: Compression “higher”, at least 200 DPI. |
| August 9 | With Compression “higher” (even advised in the Xerox press statements) and an even more generous resolution 300 DPI I reproduced number mangling on a Xerox device. As I think this is a big deal as anyone could be affected, I told Xerox and wait until they confirmed to see number mangling with the same settings, too. They confirm, and after that I wrote a detailed blog post about this. |
| August 11 | On a Xerox WorkCentre 7545, all three compression modes seem to be affected. A user reports the same using a WC 7655. In these cases, numbers seem to be mangled independently from the compression mode, which makes the issue hard to avoid. See blog post. |
| August 12 | Xerox scanning issue fully confirmed. They indeed implemented a software bug, eight years ago, and indeed, numbers could be mangled across all compression modes. They have to roll out a patch for hundreds of thousands of devices world-wide. On one hand, the implications might be of vital significance for Xerox now. On the other hand, I am glad not to go down in history as the guy too dumb to read the manual.  Here is their press statement. Here is their press statement. |
| August 19 | Pretested the Xerox number mangling patch today. Looks good. Pattern matching completely eliminated, hundreds of thousands of devices affected. |
| August 22 | First patches for Xerox scanning bug releasted. Because of the large number of affected device types, the patches are going to be released in several waves. |
| Sept 11 | I keep getting asked why I did not demand money from Xerox: There are reasons for this way of proceeding. Click here for a blog post on this. |
| From this day on | Xerox has a decentral way of selling. As a result, there is no central customer list. Consequently it is unclear how many devices have been patched yet. I would suspect there are still hundreds of thousends devices out there, producing subtly incorrect documents for 9 years now. So: Spread the word. |
| March 2015 | The German Federal Office for Safety in Information Technology bans JBIG2 from being used for archival purposes. |
Examples and how we found out
We got aware of the problem by scanning some construction plan last Wednesday and printing it again. Construction problems contain a boxed square meter number per room. Now in some rooms, we found beautifully lay-outed, but utterly wrong square meter numbers. You really have to read the numbers to find out; this is why it is so hard to find out. In the present case, we found out because one room in the construction plan was – as the copy told us – about 22 square meters large, whereas the next room, a lot larger, was assigned a label with 14 square meters.
Firstly, I present to you a complete original version of the affected construction plan part. After this, the wrong numbers will be presented. Click to enlarge. I added the yellow marks myself to show you where the errors will occur. Let us name the upper one “place 1”, the lower left “place 2” and the lower right “place 3”.
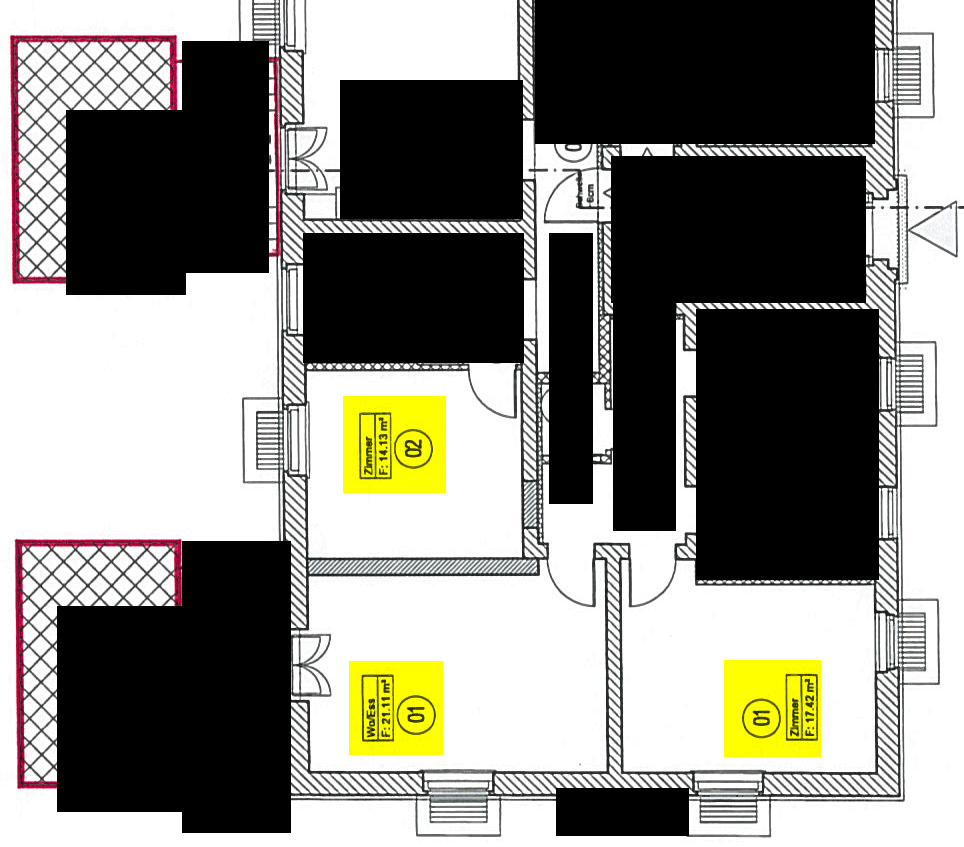
Now, let us scan the construction plan and get a PDF file from it. No OCR, just plain image. Then, we get wrong square meter numbers at the three places  (Yeah, couldn't believe it, too). The screen shots of the erroneous places are organized in the below table. There is one additional line in the table for the original patches. The Xerox WorkCentre 7535 always produced the same errors; this is why we only need one line for it in the table. In contrast, the WorkCentre 7556 randomly produced different numbers, this is why I present three lines for three runs with different errors.
(Yeah, couldn't believe it, too). The screen shots of the erroneous places are organized in the below table. There is one additional line in the table for the original patches. The Xerox WorkCentre 7535 always produced the same errors; this is why we only need one line for it in the table. In contrast, the WorkCentre 7556 randomly produced different numbers, this is why I present three lines for three runs with different errors.
| Run / Machine | Place 1 | Place 2 | Place 3 |
|---|---|---|---|
| Original, aus einem Tif-Scan entnommen, Korrektheit verifiziert |  | 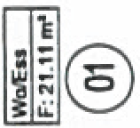 | 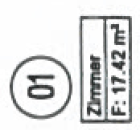 |
| Xerox WorkCentre 7535 |  |  |  |
| Xerox WorkCentre 7556, Run 1 |  |  |  |
| Xerox WorkCentre 7556, Run 2 |  |  |  |
| Xerox WorkCentre 7556, Run 3 |  |  |  |
I know that the resolution is not too fine, but the numbers are clearly readable. Additionally, obviously, these are no simple wrong pixels, but whole image patches are mixed up or copied. I repeat: This is not an OCR problem, but of course, I can't have a look into the software itself, maybe OCR is still fiddling with the data even though we switched it off.
Next example: Some cost table, scanned on the WorkCentre 7535. As we are used to, a correct-looking scan at the first glance, but take a closer look. This error was found because usually, in such cost tables, the numbers are sorted ascending.
| Before | After |
|---|---|
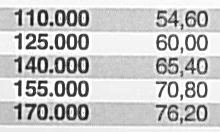 |  |
The 65 became an 85 (second column, third line). Edit: I'm getting emails telling me that also a 60 in the upper right region of the image became a 80. Thanks! This is not a simple pixel error either, one can clearly see the characteristic dent the 8 has on the left side in contrast to a 6. This scan is several weeks old – no one can say how many wrong documents have been produced by the Xerox machines in the mean time.
Affected Devices
As the saga unfolded itself, in this section I built up a “hearsay list of affected devices” according to mails my readers sent to me. As the bug is confirmed by xerox in the meantime, I was able to remove the word “hearsay”. The letter x can be substituted by arbitrary digits in cases where whole device families are affected.
| WorkCentre | 232, 238, 245, 255, 265, 275, 5030, 5050, 51xx, 56xx, 57xx, 58xx, 6400, 7220, 7225, 75xx, 76xx, 77xx, 78xx |
|---|---|
| WorkCentre Bookmark | 40, 55 |
| WorkCentre Pro | 232, 238, 245, 255, 265, 275 |
| ColorQube | 8700, 8900, 92xx, 93xx |
Reproducing the error
After the cost table, I printed some numbers, scanned them, OCRed them and compared them to the original ones. As the OCR produces errors, by itself, one obviously has to check by hand for false positives when performing this. I took Arial, 7pt as a test font, and the WorkCentre 7535 with the newer of the aboved named Software version as a test machine. The scan settings were like above. And again, a lot of sixes were replaced by eights: (only a few of the errors are marked yellow for the sake for laziness):
| Before | After |
|---|---|
 |  |
Observe how the sixes around the false eights look correct. Also the false eights contain the characteristic dent again, so whole image patches have been replaced again.
In case you want to have a look for yourself:
- An error-free TIF scan of the page. YOU CAN PRINT THIS AND CHECK ON YOUR MACHINES IF THE ERROR OCCURS.
- The first page of the PDF scan with a few marked false eights mixed in by the 7535 WorkCentre. The OCR was added by me later to be able to mark the numbers nicely, so be aware it may not be the original file, even though the image data in it is.
- Due to the popular demand: All pages of the PDF scan without any post processing, just like they came out of the 7535. Lots of pages.
Cause of error and legal implications
The error does occur because image segments, that are considered as identical by the pattern matching engine of the Xerox scan copiers, are only saved once and getting reused across the page. If the pattern matching engine works not accurately, image segments get replaced by other segments that are not identical at all, e.g. a 6 gets replaced by an 8. In contrast to what Xerox suggests in their PR, this may also happen on characters, that were perfectly readable on the original, even though they were small.
It is important to notice that the image format used in the affected PDFs, JBIG2, is an image format and not a compression algorithm. It is no instruction of how to compress an image, it only defines in what format it should be saved afterwards. So to say, it is a decompression instruction. How you compress depends on you. JBIG2 has been created to save images that contain scanned text in an efficient way and in this way it is widely used. That allows us to nevertheless have look at how compression is done usually, even though we can't look in the source code of the Xerox or other machines. In particular we will see that encoding can be done lossless or lossy. Consequently, the error cause described in the following is a wrong parameter setting during ancoding. The error cause is not JBIG2 itself. Because of a software bug, loss of information was introduced where none should have been.
JBIG2, the image format used in the affected PDFs, usually has lossless and lossy operation modes. Pattern Matching & Substitution“ (PM&S) is one of the standard operation modes for lossy JBIG2, and “Soft Pattern Matching” (SPM) for lossless JBIG2 (Read here or read the papery by Paul Howard et al.1)). In the JBIG2 standard, the named techniques are called “Symbol Matching”.
PM&S works lossy, SPM lossless. Both operation modes have the basics in common: Images are cut into small segments, which are grouped by similarity. For every group only a representative segment is is saved that gets reused instead of other group members, which may cause character substitution. Different to PM&S, SPM corrects such errors by additionally saving difference images containing the differences of the reused symbols in comparison to the original image. This correction step seems to have been left out by Xerox.
For PDFs that were scanned with the named Xerox devices during the last 8 years, it cannot be proven what characters were on the original sheet of paper at the places that are now defined by reused patches. Therefore, these patches have no legal value at all. Please note that it is irrelevant if errors actually occured in a specific scan – the legal value is zero once it is proven that lossy jbig 2 is used.
Is your company affected by the Xerox Scanning Bug?
More and more known enterprises reach out ot me these days, asking theirselves if they have a huge problem with their scanned documents. Others are already certain thay actually have a huge problem, some of them in security critical contexts. All have in common that they understandably are afraid of publicity. Affected companies normally have three goals:
- They want to solve the problem, if possible, retroactively
- They don't want publicity, enterprises with lots of employees don't even want the information published internally
- They want to stay eligible for compensations, i.e. they have to be careful not to destroy evidence by solving the problem.
At a closer look, these goals may contradict each other; even large and well-organized enterprises are prone for beginner's mistakes here. Thus, in general: Everyone who gets in touch with me requesting help to evaluate their own situation can be certain not to get his identity made public by me. I acted this way across the entire xerox saga and I won't stop this way of acting now. My contact data can be found in the imprint.