
![]()
SpiegelMining: Kassen- und Privat-Artikel. Das Zweiklassensystem von SpiegelOnline
Im letzten Artikel hatten wir uns gewundert, dass bei manchen Spiegelartikeln die Autorennamen ausgeschrieben unter dem Titel zu finden sind und andere Artikel nur eine Kürzelliste unten am Ende haben. Diesem Phänomen rücken wir heute zu Leibe, denn es gibt dahinter einen – für mich überraschenden – Sinn. Eigentlich wollte ich heute über was anderes schreiben, aber das gibt es dann nächstes mal.
Was bisher geschah: Das hier ist der dritte Artikel meiner Serie „SpiegelMining“. Im ersten Artikel haben wir gelernt, wie ich über die letzten 2 Jahre über 70.000 Artikel von SpiegelOnline heruntergeladen habe und nun auswerte. Wir hatten Zusammenhänge zwischen Erscheinungszeitpunkt Rubrik Textlänge gefunden. Im zweiten Artikel haben wir die Autoreninformationen zu jedem Artikel hinzugezogen, das soziale Netzwerk zwischen den Autoren errechnet und analysiert.
Ich hatte mich beim Parsen der Autoren-Informationen rechtschaffen darüber geärgert, dass die Autoren zu den Artikeln manchmal ausgeschrieben direkt unter dem Titel stehen, und sehr oft einfach in einer kursiv geschriebenen Zeile unter dem Haupttext. Stehen die Autoren unten, sind sie auch meist nicht ausgeschrieben, sondern in Kürzeln verschleiert. Das hat mir wirklich Arbeit gemacht. Damit wir wieder reinkommen, wiederhole ich die zwei Beispiele aus dem letzten Artikel:
In diesem Artikel über den Würzburger Axtmörder findet sich direkt unterhalb des eigentlichen Inhalts eine kursive Autorenangabe in Kürzeln: sms/dpa/AFP/Reuters. Wie wir sehen, sind dort auch die Nachrichtenagenturen enthalten.

Dann gibt es andere Artikel wie diesen hier über Donald Trump, wo keine Autorenangabe unten nach dem Text kommt, dafür aber ausgeschriebene Namen der Autoren direkt unter dem Titel stehen:
Gucken wir mal, wie oft die Autoreninfos über alle Artikel hinweg oben und unten zu finden sind, damit wir ein Gefühl für die Daten bekommen.
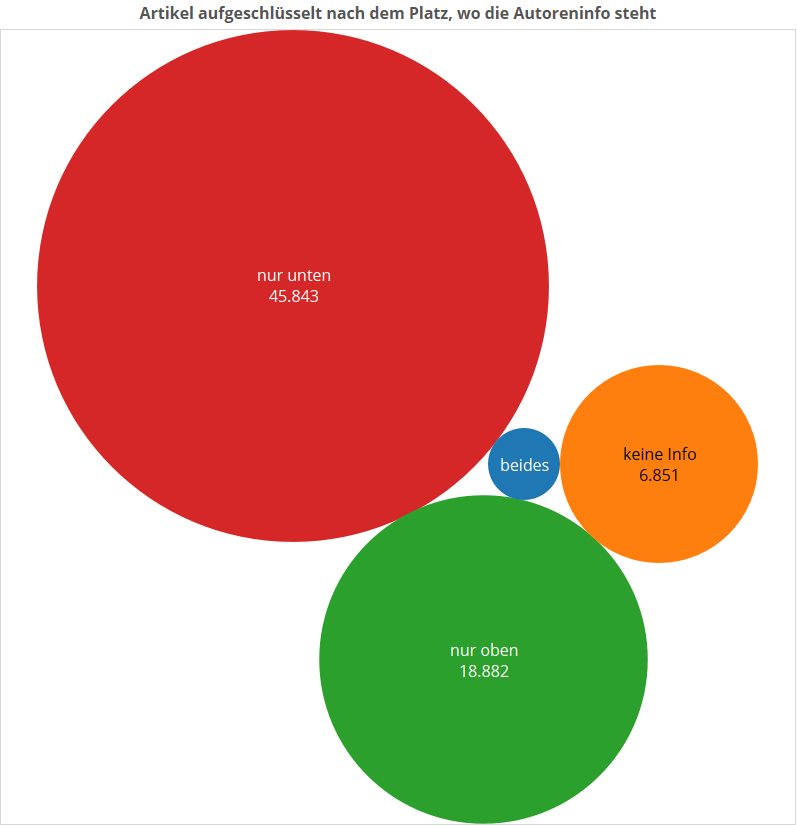
Die große Mehrheit, nämlich 63% aller Artikel, hat nur unten eine Autoreninformation (da dann wohl meist mit Kürzeln). Ca. 26% haben nur oben eine Autoreninfo (das sind die ausgeschriebenen). Ungefähr 9,5% haben gar keine Info, weder oben noch unten, und ca. 1,2% haben oben und unten irgendwas. Die Artikel ganz ohne Infos können ein paar Messfehler enthalten, sind aber auch teilweise keine Artikel im eigentlichen Sinne (Livestreams zum Beispiel).
Zeitliche Veränderungen über diese Anteile gibt es auch keine auf den ersten Blick auffälligen: 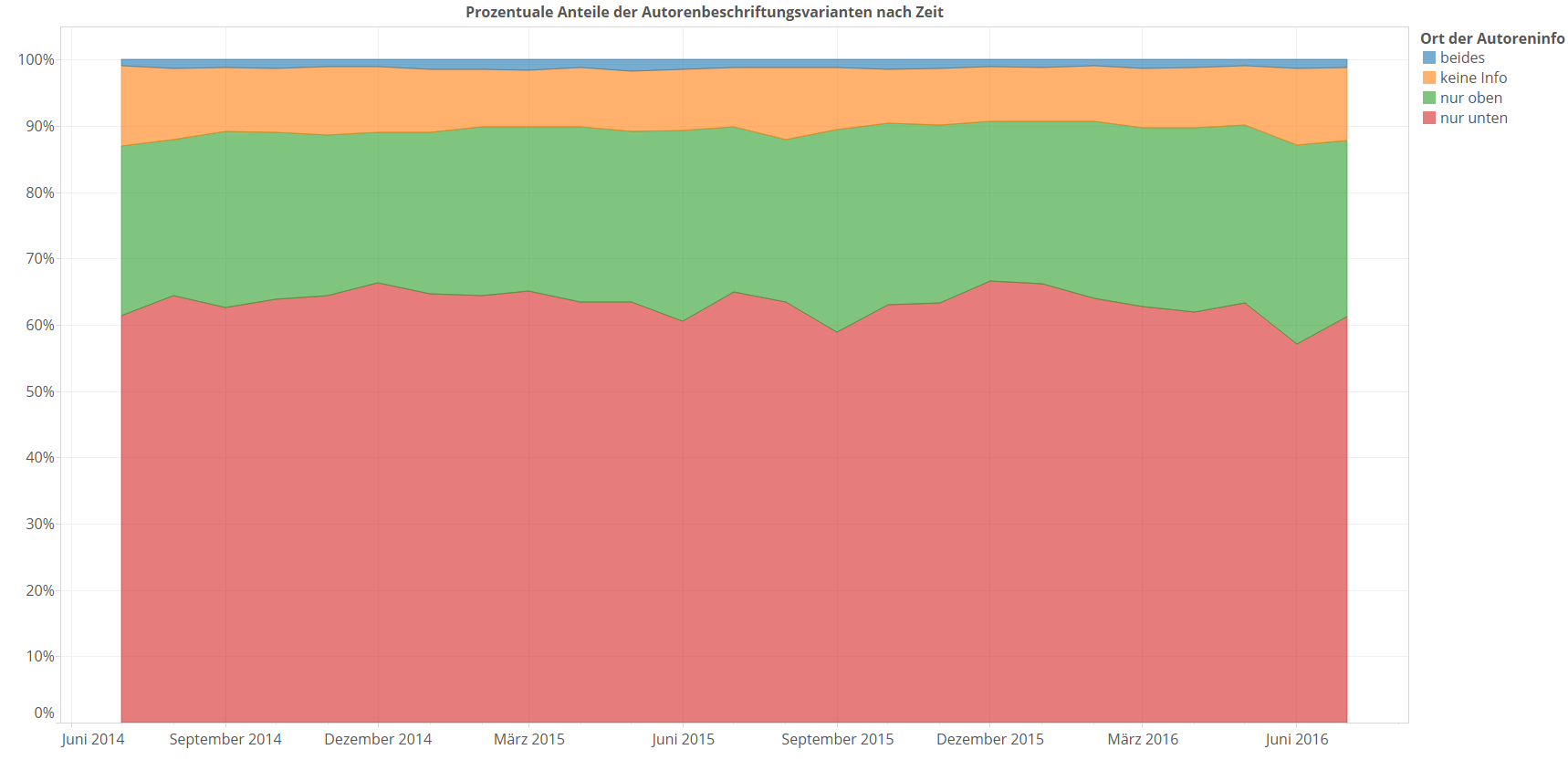
Was könnte SpiegelOnline nun verleiten, bei manchen Artikeln die Realnamen der Autoren hervorheben zu wollen, und bei manchen zu verschleiern? Wohlgemerkt kann man sich, wenn man die Namen der Autoren zu den Kürzeln wissen will, im Impressum umgucken, das hatte ich ja im letzten Artikel schon genannt. Worum geht es also dabei?
Ein spontaner Einfall von mir war: Journalisten und auch Medienhäuser sind naturgemäß sehr auf ihr Image in der Öffentlichkeit bedacht und wissen auch mehr als der Durchschnittsbürger darüber, wie man ein solches erzeugt und vernichtet. Dabei spielt das Internet natürlich eine große Rolle. Wenn ich also ohnehin sehr viele Artikel schreibe, weil ich Journalist bin, dann kann ich auch einfach dafür sorgen, nur unter den allerbesten davon Googlebar zu sein!
Wer mich als Journalist googelt, soll bitte viele exzellente Artikel finden, und nicht den ganzen Crap, den ich sonst noch so am Tag raushauen oder von DPA abschreiben muss, weil der Job es eben gerade erfordert.
Meine These war also: Artikel mit ausgeschriebenen Namen sind erste Wahl, bzw. „HighQuality“. Mit denen hat sich der Autor mehr Mühe gegeben. Artikel ohne ausgeschriebene Namen zweite Wahl. Ausgeschrieben werden die Namen in der Regel oben unter dem Titel, während es unten fast nur Kürzel gibt. Also wären Artikel, die die Autoreninfo oben haben, die erste Wahl und der Rest die Zweite.
Nun ist die Frage: Wie misst man, ob sich ein Autor Mühe gegeben hat? Das ist sehr schwer. Aber es gibt einen Indikator: Wie lang der Text ist. Verschaffen wir uns also zuerst mal einen Überblick darüber, wie die Verteilung der Textlängen bei SpiegelOnline so ist. Im ersten Artikel hatten wir das im Hinblick auf Rubriken und Tageszeiten gemacht, aber wir hatten nicht nur einfach mal die Verteilung aller Textlängen angeschaut, weil ich damals nicht noch eine zusätzliche Art Diagramm einführen wollte. Das holen wir jetzt nach.
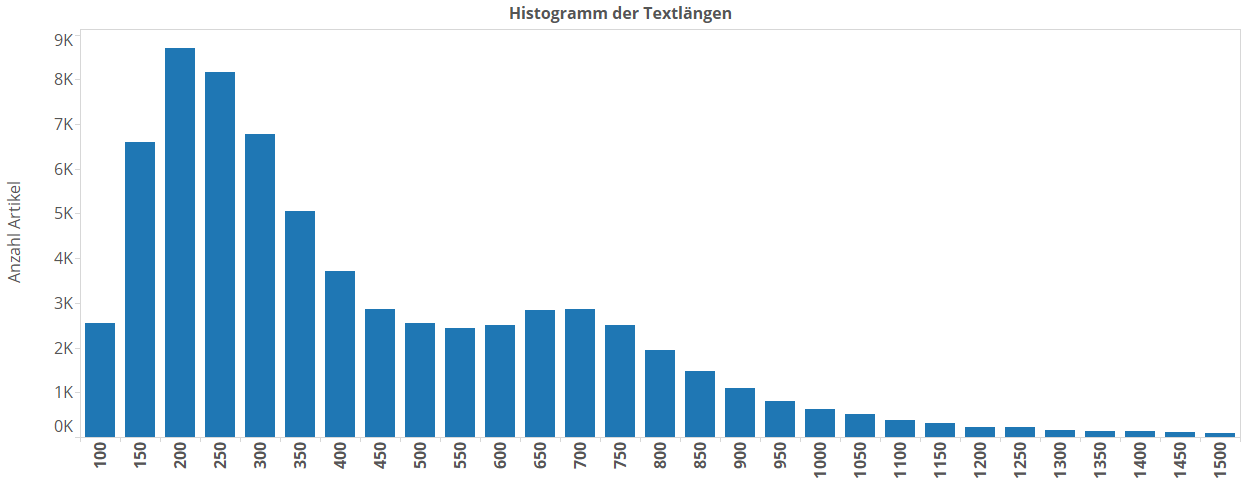
Diese Art Artikel nennt sich Histogramm und ist gut geeignet, um Verteilungen darzustellen. Die X-Achse ist die Textlänge. Jeder Balken gibt an, wieviele Artikel es mit ungefähr seiner Textlänge gibt. Würde sich eine große Häufung rechts ausbilden, gäbt es viele eher lange Artikel. Ein großer Haufen links bedeutet, dass es viele eher kurze Artikel gibt. Ein Histogramm ist häufig eine sehr gute Wahl um sich mal ein Bild über Besonderheiten in einem Merkmal der Daten zu machen. Wäre eine riesige Spitze z.B. bei exakt 753 Worten, könnte man sich überlegen, ob es da vielleicht eine Regel gibt, die solche Artikel fördert und warum. So etwas sieht man hier nicht.
Die allermeisten Texte bei Spiegelonline spielen sich zwischen 100 und 1500 Wörtern ab (das Histogramm ist zu beiden Seiten beschnitten, weil da kaum noch was kam). Wie man sieht gibt es einen großen Knubbel Artikel, die zwischen 100 und 500 Worten lang sind. Das sind schon deutlich über die Hälfte, nämlich knapp 46.000 Artikel (ca. 65%). Danach gibt es noch mal eine weitere Spitze um die Textlänge von 700 herum, und je länger die Textlänge ab da wird, um so weniger Artikel kommen noch hinzu.
Jetzt machen wir mal den Anteil derjenigen Artikel sichtbar, die oben unter dem Titel eine Autoreninfo haben (wir erinnern uns: Das sind die mit ausgeschriebenen Autorennamen, hinter diesen Artikeln vermuten wir hohe Qualität und damit längere Texte):
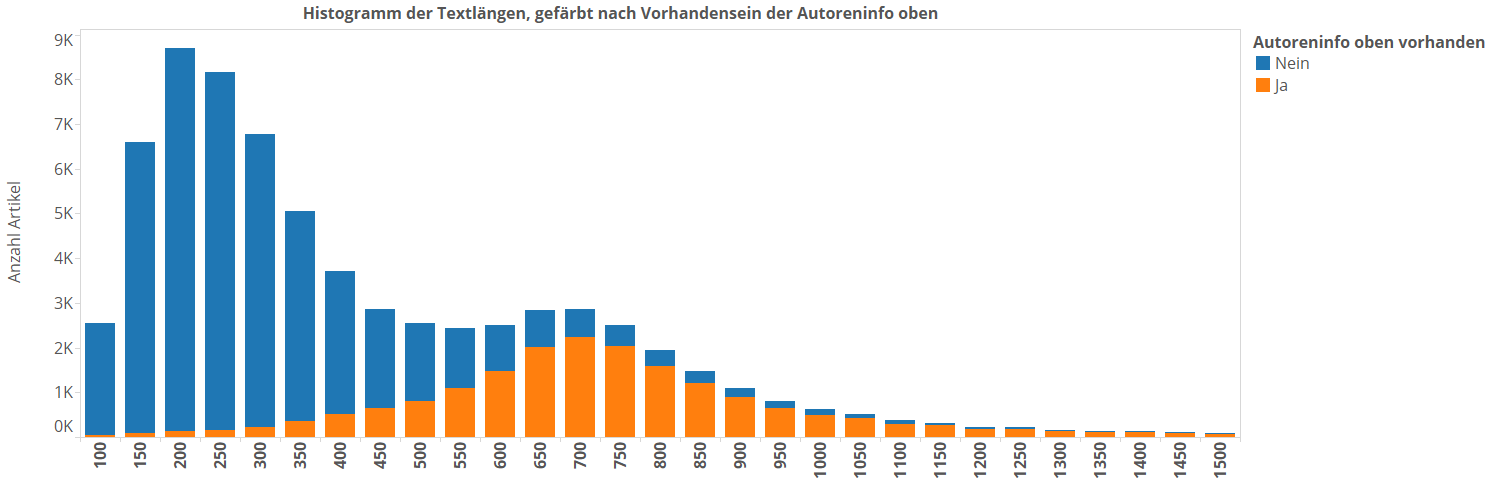
Die orangen Blöcke sind mit ausgeschriebenen Autoren. Und siehe da – Bingo! Es gibt einen auffälligen Textlängenunterschied. Spiegel fährt ein klares Zwei-Klassen-System. Die Artikel, bei denen Autoren namentlich genannt sind, haben eine ganz andere Textlängenverteilung als diejenigen ohne namentlich genannte Autoren.
Die ohne Autoren haben den Median (also die Textlänge, die in der Mitte liegt, wenn man alle diese Artikel nach Textlänge sortiert) bei 291 Worten. Artikel mit namentlich genanntem Autor sind dagegen im Median über 2.5 mal so lang (739 Worte). Das ist mal ein sichtbarer Unterschied!  Ich sollte dringend darüber nachdenken, bei den kürzeren meiner Blogartikel meinen Klarnamen durch „dkr“ zu ersetzen. Die orangen „HighQuality“-Artikel sind überhaupt das, was den die zweite Häufung erzeugt. Von allen Artikeln sind übrigens ca. 27% HighQuality, der Rest ist LowQuality.
Ich sollte dringend darüber nachdenken, bei den kürzeren meiner Blogartikel meinen Klarnamen durch „dkr“ zu ersetzen. Die orangen „HighQuality“-Artikel sind überhaupt das, was den die zweite Häufung erzeugt. Von allen Artikeln sind übrigens ca. 27% HighQuality, der Rest ist LowQuality.
Jetzt ist der erste Moment, wo ich eine relativierende Anmerkung bezüglich meiner ketzerischen Überschrift machen kann. Die ist im Grunde falsch! Kassen- und Privatartikel suggerieren, dass man für die Privatartikel bezahlen muss, oder dass diese nur ausgewählten Personen zur Verfügung stehen. Das ist nicht der Fall. Sowohl Kassen- als auch Privatartikel stehen Jedermann zur Verfügung. Hängt dem Spiegel also nicht wegen meiner absichtlich überspitzten Überschrift irgendeine an den Haaren herbeigezogene Sozialneiddiskussion ans Bein. Im übrigen werden die anderen Medien das ganz genauso machen.
Wir hatten ja im ersten Artikel festgestellt, dass sich die durchschnittlichen Textlängen verschiedener Rubriken teilweise erheblich voneinander unterscheiden. Ist es denkbar, dass das einfach daran liegt, dass es in den Rubriken, die für lange Texte bekannt sind, einfach mehr „benamste Qualitätsware“ gibt? Wir schlüsseln das farbige Histogramm einmal nach Rubriken auf (ich mache hier jetzt Cherry Picking und präsentiere nur die interessantesten). Und siehe da, es gibt wirklich erhebliche Unterschiede über die Kategorien hinweg.
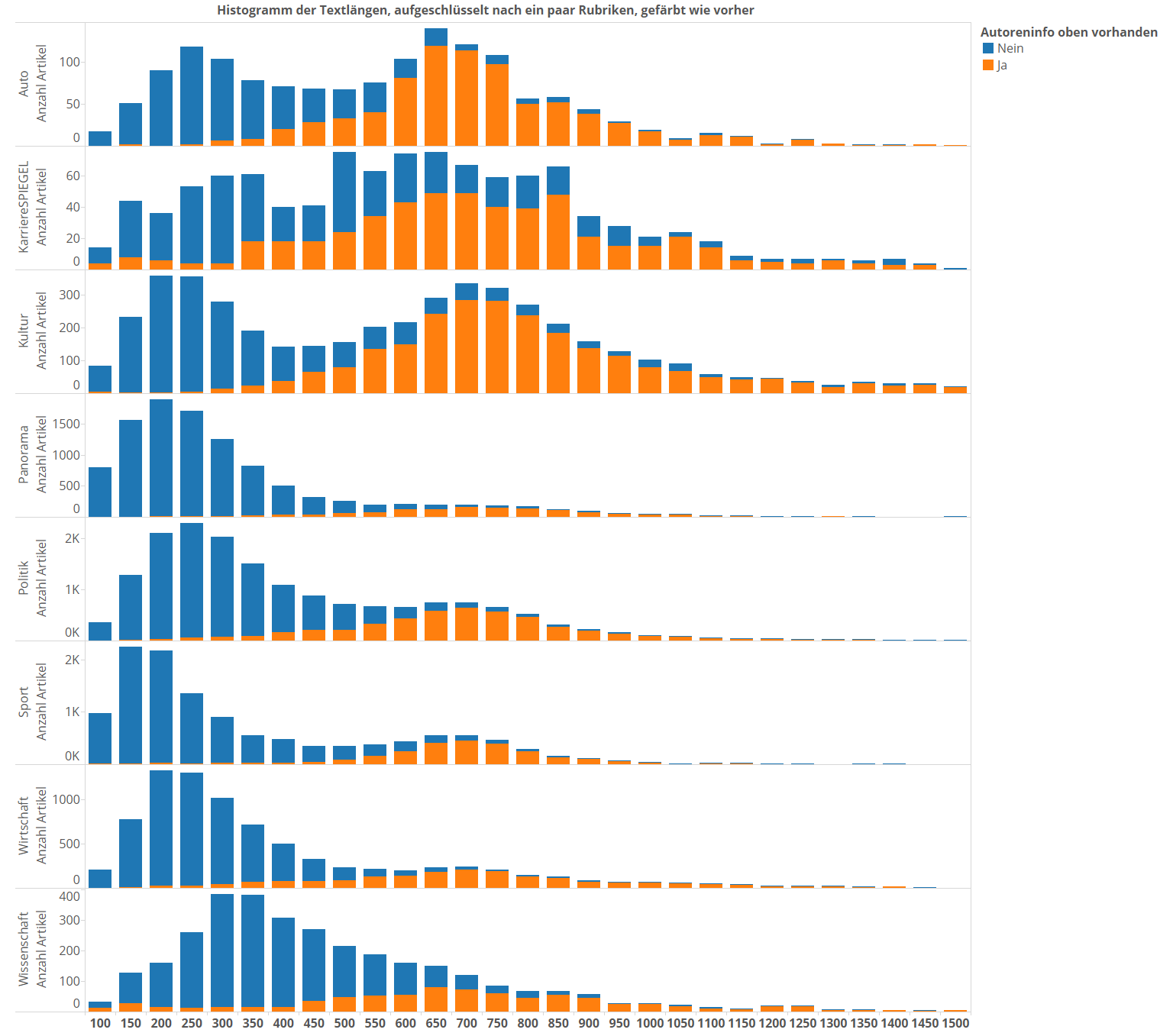
Beachtet, dass die Sub-Plots unabhängige Y-Achsen haben. Das ist, damit die dominierenden Rubriken nicht alle anderen plattdrücken.
Bei den Rubriken Auto, KarriereSPIEGEL und Kultur kann man anscheinend übergreifend so stolz auf seine Artikel sein, dass man damit in Google genannt werden will. Ein großer Teil der dortigen Artikel enthält Namensnennungen bei den Autoren. Panorama, Sport, Wirtschaft, Wissenschaft … ach, lassen wir das am besten.  Politik ist so im unteren Mittelfeld. Beachtet, dass Politik, Panorama und Sport die drei dominierenden Kategorien sind. Hier ist der Output so hoch, dass man vielleicht einfach viele Artikel schreiben muss, für die man lieber nicht genannt werden will.
Politik ist so im unteren Mittelfeld. Beachtet, dass Politik, Panorama und Sport die drei dominierenden Kategorien sind. Hier ist der Output so hoch, dass man vielleicht einfach viele Artikel schreiben muss, für die man lieber nicht genannt werden will.
Das ist auch ganz natürlich: Gerade im Panorama spielt sich das Tagesgeschehen ab. Habt ihr mitverfolgt, vieviel Bullshit beim Münchner Amoklauf unter dem Deckmantel der Liveberichterstattung durch die Medien ging, bis überhaupt mal irgendwas klar war? Ihr würdet neben so einem Crap auch nicht googelbar sein wollen.
Wir fassen noch mal alle Rubriken in einen Plot zusammen, aber ohne die genaue Verteilung, dafür geordnet nach Rubrikvolumen:
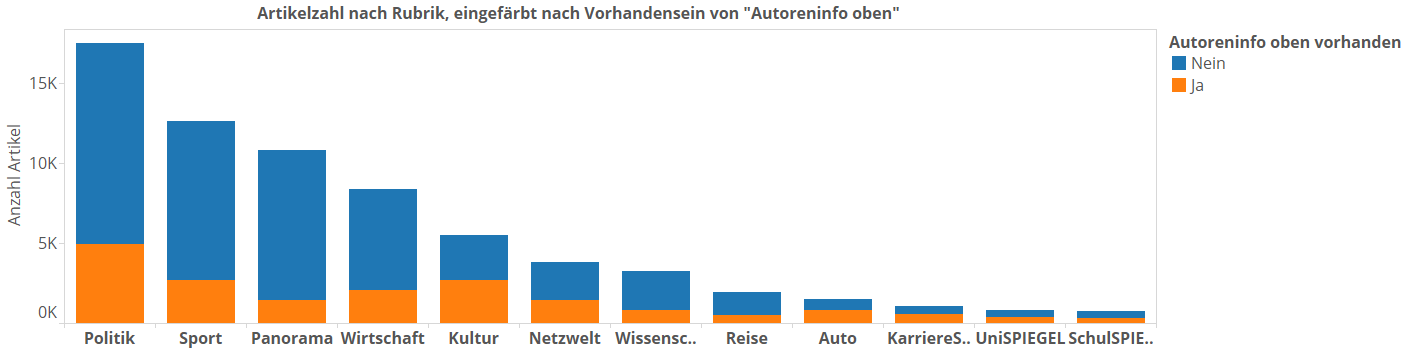
In der Tat, insgesamt steigt zwar mit größerem Rubrikvolumen auch die Anzahl der HighQuality-Artikel. Es ist also nicht so, dass es eine feste Anzahl an HighQuality-Artikeln in jeder Rubrik gibt, und wer als Rubrik halt zu groß ist, hat Pech. Aber es gibt in diesem Anstieg stramme Löcher, besonders sichtbar bei Panorama.
Um uns ein abschließendes Bild zu verschaffen, ziehen wir mal alle Balken mal hoch bis an die obere Bildgrenze. So verlieren wir zwar das Gefühl fürs Rubrikvolumen, können aber dafür die Anteile der HighQuality-Artikel pro Rubrik besser vergleichen:
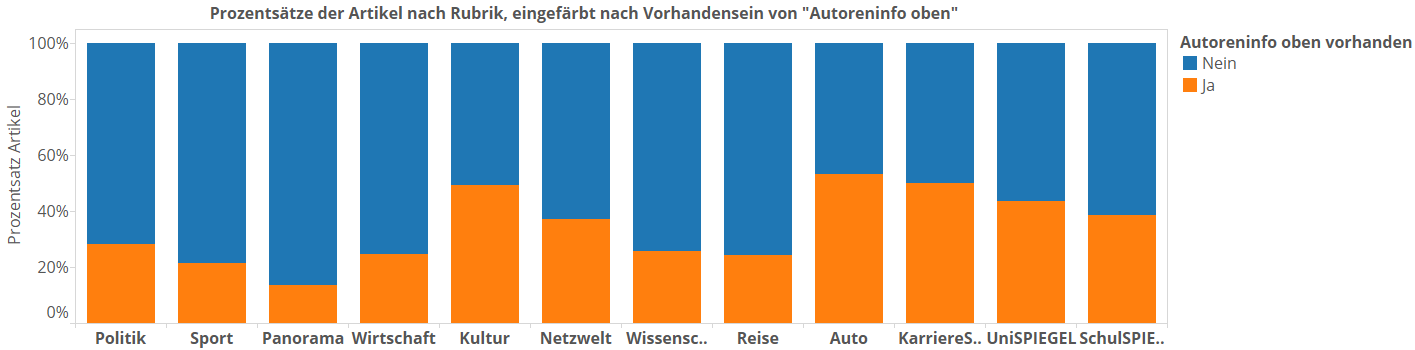
Da sieht man erstmal, wie klein der Anteil an HighQuality-Artikeln im Panoramateil eigentlich ist. Und gleichzeitig ist der Kulturteil sogar nur zweiter hinter der Autorubrik. Na, es ist eben Deutschland hier. 
Wir könnten das übrigens auch pro Autor machen: Messen, wie hoch der Anteil an HighQuality-Artikeln ist. Finde ich aber nicht gut, denn das wird erstens sehr verzerrt sein, weil die Autoren extrem unterschiedliche Artikelmengen publizieren, und zweitens denke ich nicht, dass sie da selbst Einfluss auf ihre guten oder schlechten Werte haben, also werde ich hier niemanden irgendwelchem Internetgebrabbel aussetzen.
Aber vielleicht erinnert ihr euch, dass wir im ersten Artikel gemerkt hatten, dass die Länge von Artikeln sehr stark von der Tageszeit und dem Wochentag abhing? Wir wiederholen das mal kurz. So sah das aus:
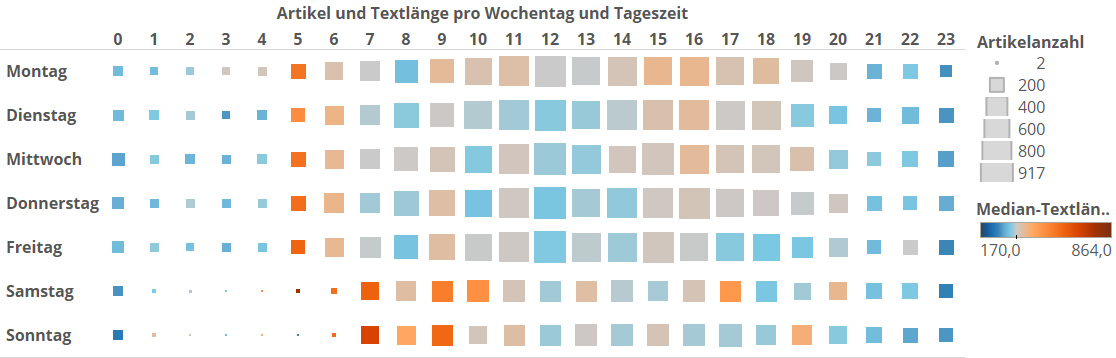
Und jetzt gucken wir mal, wann die HighQuality-Artikel so veröffentlicht werden. Hier ist wieder eine Heatmap. Sie ist eingefärbt je nach dem, wie hoch der Anteil der HighQuality-Artikel in der Zelle ist. Wir haben im Schnitt 27% HighQuality-Artikel. Das entspricht in der Grafik einem unauffälligen Grauton. Rote Zellen liegen über diesem Wert, blaue Zellen darunter. Je knackiger die Farbe, desto weiter liegen sie drüber bzw. drunter.
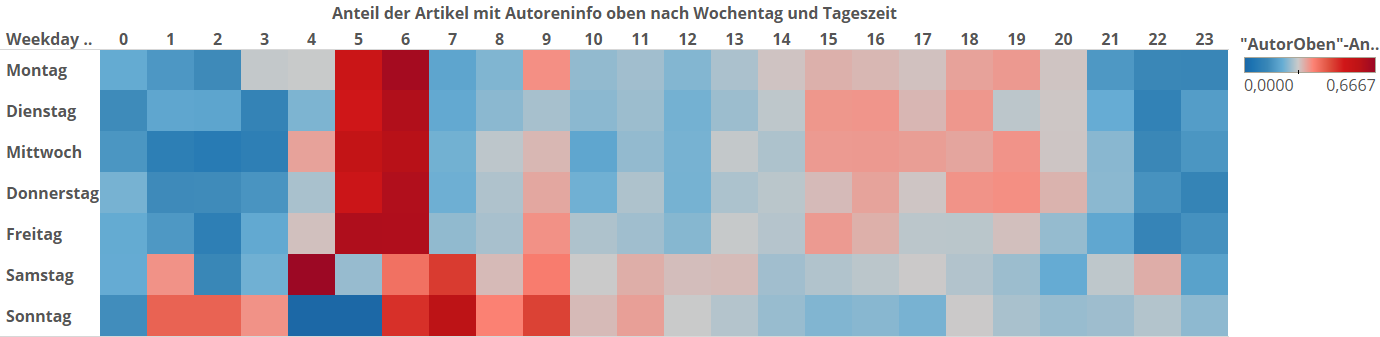
Siehe da – die Farbgebung korrespondiert sehr genau zu unserer Analyse von damals, wo wir die Artikellänge nach Wochentag und Stunde analysiert haben. An Wochentagen zwischen 5 und 7 Uhr werden weit überdurchschnittlich viele HighQuality-Artikel veröffentlicht. Am Wochenende weiter über den Tag hinweg. Die knallrote Zelle Samstags zwischen 4 und 5 Uhr ist insofern ein Ausreißer, als dass sie insgesamt nur drei Artikel enthält. Von denen sind dann direkt mal zwei HighQuality, weil sie aufgrund spezieller Ereignisse zu dieser Zeit geschrieben wurden (Pariser Terror und Putschversuch in der Türkei). Da waren wir in unserem ersten Artikel schon dem spiegelinternen Zwei-Klassen-System auf der Spur, ohne es zu wissen.
Was wir noch gar nicht betrachtet haben, sind die Nachrichtenagenturen, die ich ebenfalls als Autoren miterfasse und separat zähle. Als letzte Analyse für heute schauen wir darum mal, wie viele Autoren zu einem Artikel beigetragen haben, und zu wievielen Artikeln durchschnittlich Nachrichtenagenturen beigetragen haben. Gerade letzteres ist nämlich ein weiterer Indikator dafür, wieviel Arbeit SpiegelOnline selbst in einen Artikel reingesteckt hat. Und diese Betrachtung spalten wir auf in HighQuality- und LowQuality-Artikel. Artikel, die gar keinen Autor verzeichnet haben (sei es aufgrund von Parsingfehlern oder einfach weil da wirklich keiner steht) sind hier gefiltert. LowQuality-Artikel sind wieder Blau, und HighQuality ist Orange.
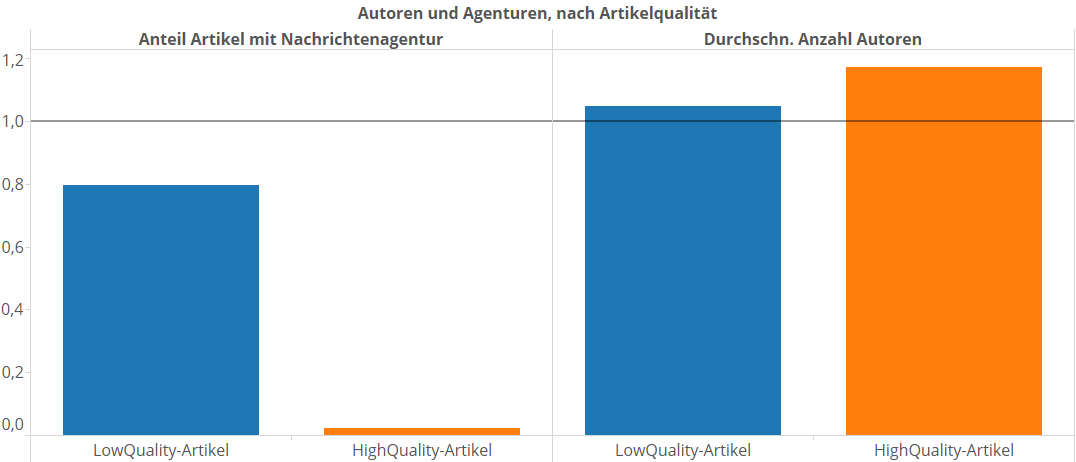
Erstmal das unspektakuläre. Bei den HighQuality Artikeln sind mit 1,17 im Schnitt etwas mehr Autoren beteiligt als bei den LowQuality-Artikeln (1,049). Aber siehe da: Bei der großen Mehrheit der LowQuality-Artikel ist wenigstens eine Nachrichtenagentur beteiligt (= die Artikel stammen nicht komplett oder gar nicht aus der Feder von SpiegelOnline). Bei den HighQuality-Artikeln ist der Anteil der Artikel mit Nachrichtenagentur dagegen extrem klein. Die HighQuality-Artikel sind, grob gesagt, die selbstgeschriebenen. Ich gucke mal in die Daten und mache das noch etwas genauer, damit wir nicht nur die Durchschnittswerte haben:
- Von den HighQuality-Artikeln ist nur bei 2,2% eine Agentur mit im Spiel.
- Von den LowQuality-Artikeln ist bei satten 79,6% wenigstens eine Agentur mit angegeben.
Das ein weiteres starkes Argument dafür, dass unsere Annahme, es gebe ein stark ausgeprägtes Artikel-Zweiklassensystem, zutrifft. Also: Haltet euch an die Artikel mit ausgeschriebenen Namen unter der Überschrift, dann kriegt ihr die, die auch wirklich von SpiegelOnline selbst verfasst wurden. Wenn ihr das tut, werdet ihr allerdings nicht mehr sooo viel Panorama lesen.
Wir hatten hier ja schon mal die Frage angeschnitten, ob vielleicht im Laufe der Zeit Rubriken zusammengestutzt oder erweitert werden. Indikatoren für sowas können ein sinkender Artikeloutput pro Zeit oder eine sinkende Anzahl an verschiedenen Mitarbeitern über die Zeit in einer Rubrik sein. Mit dem Wissen, was wir jetzt haben, können wir mal den Anteil der HighQuality-Artikel über die Zeit sichtbar machen. Das ist ein viel subtilerer Indikator für Zusammenstreichungen, weil er vom Leser viel weniger bemerkt wird, als wenn eine Rubrik plötzlich stark an Output verliert oder der Lieblingsredakteur dort wechselt. Das ist sowas, was man als Leser nach einem halben Jahr irgendwie unscharf im Bauch bemerkt in Form eines Gefühls wie „hm, hat irgendwie nachgelassen, aber ich kann mit dem Finger nicht drauf zeigen.“ Hier sind ein paar ausgewählte Rubriken, bei denen ich diese Auswertung mal gemacht habe (der Rest ist unauffällig):
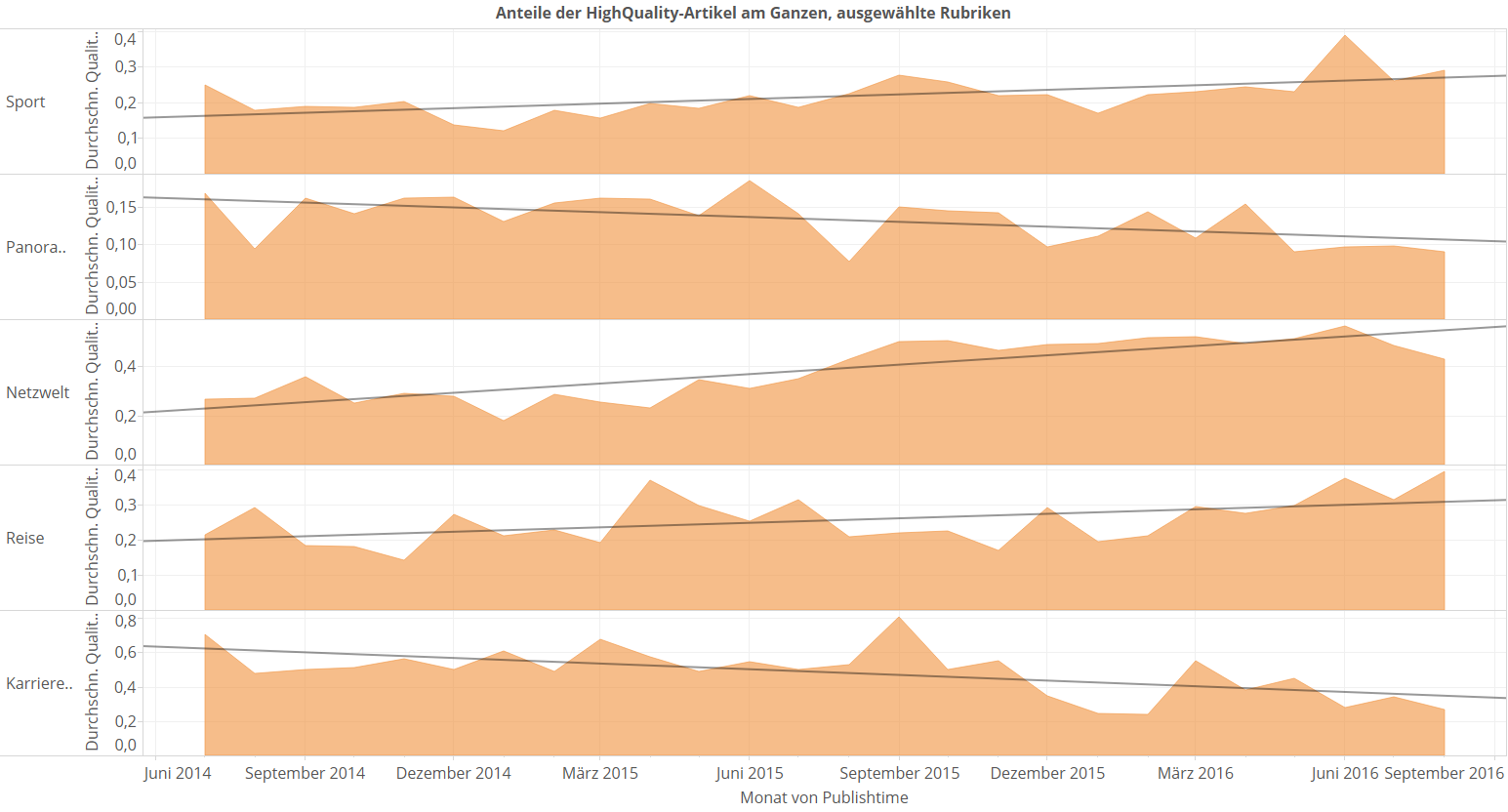
Beachtet die Trendlinien, und dass wir jetzt wieder unabhängige Y-Achsen für die einzelnen Sub-Plots haben (sonst drücken die Rubriken mit hohem Qualitätsanteil die anderen platt, und man sieht nichts mehr). Beim Sport steigt der Anteil der HighQuality-Artikel an, das kann aber auch ein Effekt der EM und Olympischen Spiele sein, die jetzt gerade stattgefunden haben bzw. stattfinden. Panorama hatten wir oben schon als Rubrik mit extrem niedrigem Anteil von HighQuality-Artikeln identifiziert, und was soll ich sagen? Er sinkt noch weiter („nach schwachem Anfang stark abgefallen“). Definitiv auf dem aufsteigenden Ast ist die Netzwelt, hier wird anscheinend seit Mitte 2015 mehr investiert. Der Anstieg der gemessenen Qualität in den Reise-Artikeln ist wieder ein gutes Beispiel von einer saisonalen Schwankung: Jetzt ist gerade Reisezeit, also kommt eine steigende Tendenz wahrscheinlich schon daher raus, weil wir eben jetzt gerade aufgehört haben, zu messen. Beim Karrierespiegel ist der Anteil der High-Quality-Artikel stark sinkend, war aber auch vorher vergleichsweise hoch.
Ein sehr versöhnliches Schlusswort habe ich aber noch: Seit neuem gibt es die Bezahlartikel von SpiegelOnline, genannt SpiegelPlus (hier hatte ich mal einen Blogartikel zum Thema, wie man die entschlüsselt). Mittlerweile haben wir also ein Drei-Klassen-System. Weil es diese Art Artikel erst so kurz gibt, konnte ich darüber bis jetzt nur sehr wenig Daten sammeln. Darum kann ich für diese Art Artikel z.B. noch keine zuverlässige Artikellängen-Verteilung darstellen. Aber es reicht, um einen Textlängen-Median zu bilden.
Wir hatten oben gesagt: Artikel ohne explizite Autoren-Namensnennung (LowQuality) haben 291 Worte im Median. Die HighQuality-Artikel mit expliziter Namensnennung haben 739. Und die Bezahlartikel, die ich bis jetzt gemessen habe, haben 1111 Worte im Median.
Wenn ihr bei SpiegelPlus etwas bezahlt (und nicht nur böswillig meine Entschlüsselung nutzt  ), dürft ihr also mit Fug und Recht hoffen, für euer Geld etwas zu bekommen.
), dürft ihr also mit Fug und Recht hoffen, für euer Geld etwas zu bekommen.
Ich hoffe, euch hat dieser kleine Zwischenartikel ebensoviel Spaß gemacht wie mir. Der war gar nicht geplant, sondern ist in der Tat nur entstanden, weil mich interessiert hat, warum Autoren manchmal oben und manchmal unten im Artikel stehen. Aber das ist ja ganz natürlich bei solch einer Forschungsarbeit – man weiß nicht, wohin es einen trägt.