News
Corona-Charts: New Year's Update 2022
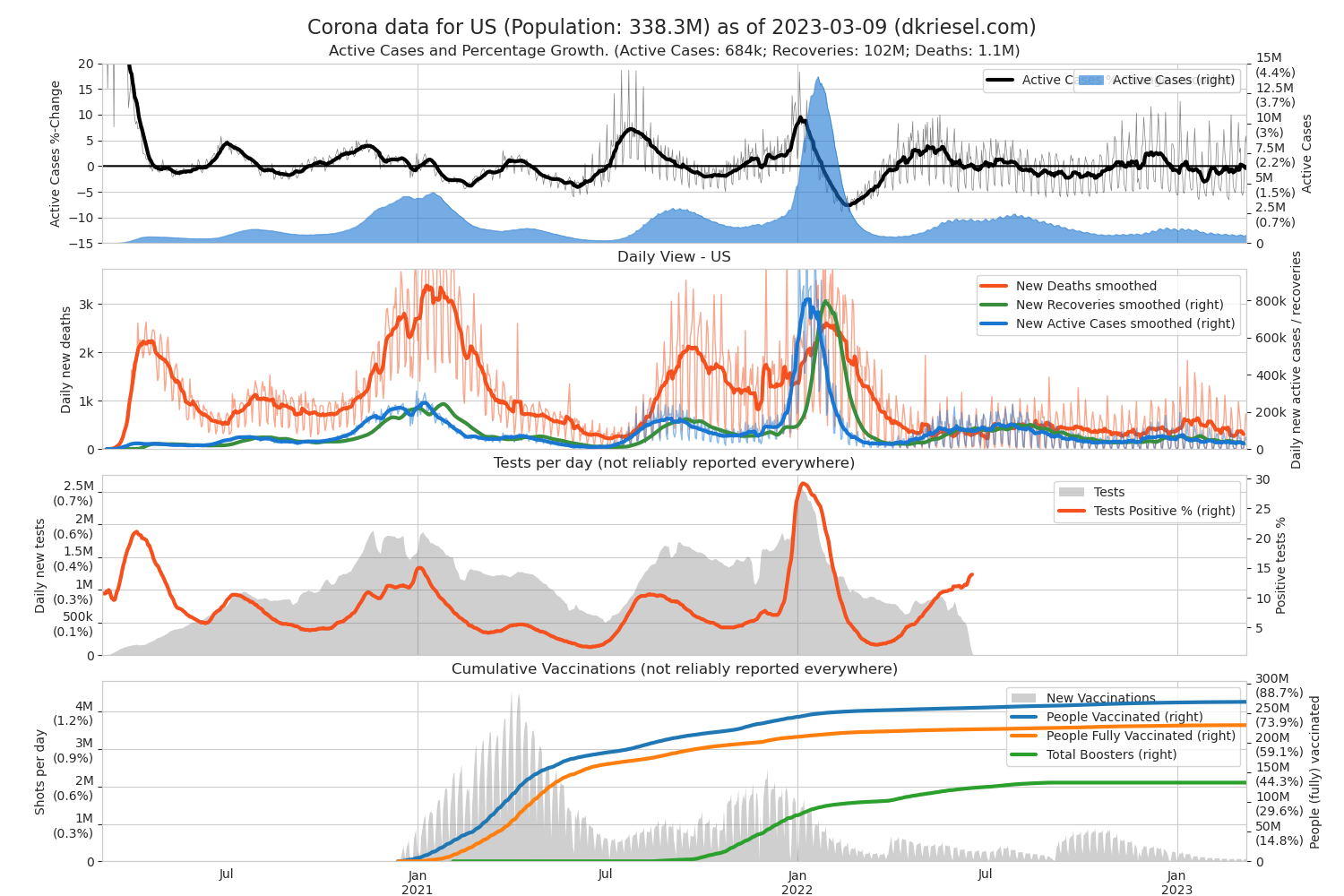
 I Updated my Covid19 plots at http://www.dkriesel.com/en/corona. The cumulative plot has now become an Active Cases plot because that is more interesting from today's perspective. In the daily plot, the Y-axes are now reversed because the Active Cases are more interesting in Omikron than the now much fewer deaths. The vaccination plot now includes booster vaccinations and is normalized to 90% of each country's population size, so you can see at a glance whether a country is doing well or poorly with vaccinations.
I Updated my Covid19 plots at http://www.dkriesel.com/en/corona. The cumulative plot has now become an Active Cases plot because that is more interesting from today's perspective. In the daily plot, the Y-axes are now reversed because the Active Cases are more interesting in Omikron than the now much fewer deaths. The vaccination plot now includes booster vaccinations and is normalized to 90% of each country's population size, so you can see at a glance whether a country is doing well or poorly with vaccinations.
Video and slides of FrOSCon 2015 talk "Lies, damned lies and scans"
 Here, as promised, the Slides (PDF, 3.8MB) and the youtube video of my Talk “Lies, damned lies and scans” at FrOSCon 2015 in St. Augustin, Germany! Thanks for inviting me, it was a lot of fun. You find the original Xerox Saga information here.
Here, as promised, the Slides (PDF, 3.8MB) and the youtube video of my Talk “Lies, damned lies and scans” at FrOSCon 2015 in St. Augustin, Germany! Thanks for inviting me, it was a lot of fun. You find the original Xerox Saga information here.
Congratz again to FrOSCon to the 10 year anniversary, and I feel honoured by the celebrity in the audience! 
Next Talk: August 22th, FrOSCon, "Lies, damned lies and scans"
 At 22th of August, I will be presenting about the Xerox-Saga at FrOSCon – looking forward to it
At 22th of August, I will be presenting about the Xerox-Saga at FrOSCon – looking forward to it  .
.
The program says that I will be starting Saturday at 5:45 PM, so if you like, I will be closing the track for this day. I undertake for an entertaining session. The language will be english this time, and as far as I have been told, there will be streams and videos again.